

When designing a model to perform a classification task (e.g. classifying diseases in a chest x-ray or classifying handwritten digits) we want to tell our model whether it is allowed to choose many answers (e.g. both pneumonia and abscess) or only one answer (e.g. the digit “8.”) This post will discuss how we can achieve this goal by applying either a sigmoid or a softmax function to our classifier’s raw output values.
Neural Network Classifiers
There are many algorithms for classification. In this post we are focused on neural network classifiers. Different kinds of neural networks can be used for classification problems, including feedforward neural networks and convolutional neural networks.
Applying Sigmoid or Softmax
At the end of a neural network classifier, you’ll get a vector of “raw output values”: for example [-0.5, 1.2, -0.1, 2.4] if your neural network has four outputs (e.g. corresponding to pneumonia, cardiomegaly, nodule, and abscess in a chest x-ray model). But what do these raw output values mean?
We’d like to convert these raw values into an understandable format: probabilities. After all, it makes more sense to tell a patient that their risk of diabetes is 91% rather than “2.4” (which looks arbitrary.)
We convert a classifier’s raw output values into probabilities using either a sigmoid function or a softmax function.
Here’s an example where we’ve used a sigmoid function to transform the raw output values (blue) of a feedforward neural network into probabilities (red):

And here’s an example where we’ve instead used a softmax function to transform those same raw output values (blue) into probabilities (red):

As you can see, the sigmoid and softmax functions produce different results.
One key point is that the probabilities produced by a sigmoid are independent, and are not constrained to sum to one: 0.37 + 0.77 + 0.48 + 0.91 = 2.53. That’s because the sigmoid looks at each raw output value separately.
In contrast, the outputs of a softmax are all interrelated. The probabilities produced by a softmax will always sum to one by design: 0.04 + 0.21 + 0.05 + 0.70 = 1.00. Thus, if we are using a softmax, in order for the probability of one class to increase, the probabilities of at least one of the other classes has to decrease by an equivalent amount.
Sigmoid Examples: Chest X-Rays and Hospital Admission
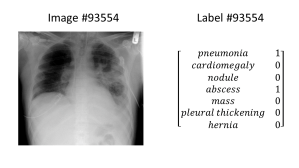
Chest X-Rays: A single chest x-ray could show many different medical conditions at the same time. If we build a classifier for chest x-rays, we want that classifier to be able to indicate that multiple conditions are present. Here’s a chest x-ray image showing both pneumonia and abscess, and the corresponding label, which you’ll notice has multiple “ones” in it:
Hospital Admission: Given a patient’s health records, we might want to predict whether that patient will be admitted to the hospital in the future. We can frame this as a classification problem: classify a patient’s past health record according to their future hospital admission diagnoses (if any.) The patient might be admitted for multiple diseases, so there is possibly more than one right answer.
Diagrams: The picture below shows two feedforward neural networks, corresponding to these two classification problems. At the end, a sigmoid function is applied to the raw output values to obtain the final probabilities and allow for more than one correct answer – because a chest x-ray can contain multiple abnormalities, and a patient might be admitted to the hospital for multiple diseases.

Softmax Examples: Handwritten Digits and Irises
Handwritten Digits: If we are classifying images of handwritten digits (the MNIST data set), we want to force the classifier to choose only one identity for the digit by using the softmax function. After all, a picture of the number 8 is only the number 8; it cannot be the number 7 at the same time.
![]()
An “eight” from MNIST. Image modified from here
Irises: The Iris dataset is a famous data set introduced in 1936. It includes 150 examples total, with 50 examples from each of the three different species of Iris (Iris setosa, Iris virginica, and Iris versicolor). Each example in the data set includes measurements of sepal length, sepal width, petal length, and petal width.
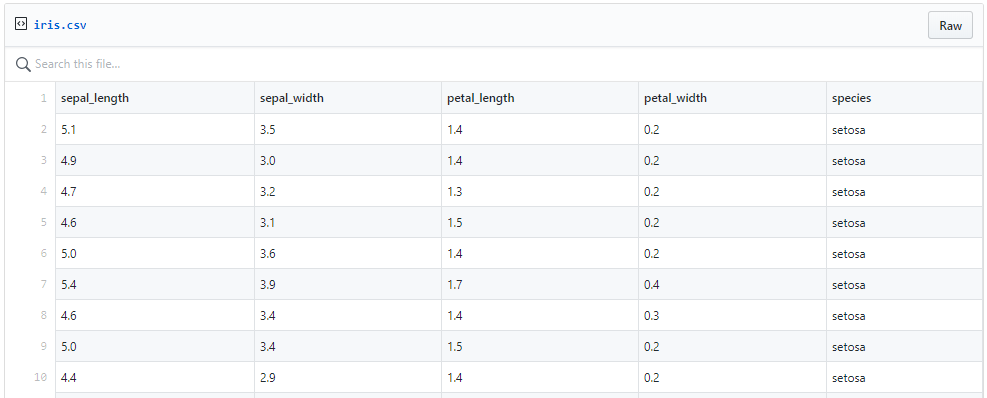
Here is an excerpt from the Iris data set showing 9 examples from the Iris setosa class:
Although the data set doesn’t contain any images, here’s a picture of an Iris versicolor, because it’s pretty:

If we build a neural network classifier for the Iris data set, we want to apply a softmax function to the raw outputs, because a single iris example can only be one species at a time – it wouldn’t make sense to predict that a single flower was multiple species at the same time.
A side note on the number “e”
In order to understand the sigmoid and softmax functions, we need to introduce the number “e” first. For the purposes of this post, all you need to know is that e is a mathematical constant equal to approximately 2.71828.
In case you want to know more, here are some fun facts about e:
- The decimal representation of e goes on forever, with no repeating block of numbers – similar to the number pi.
- e arises in studies of compound interest, gambling, and certain probability distributions.
- Here’s one formula for e:
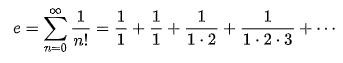
- But there isn’t just one formula for e. In fact, e can be calculated in several different ways. See this page for examples.
- In 2004, Google’s IPO filing was $2,718,281,828, or “e billion dollars.”
- Here’s a timeline from Wikipedia of the number of known decimal digits of e across human history, starting with one digit known in 1690 and continuing to 116,000 digits known in 1978:
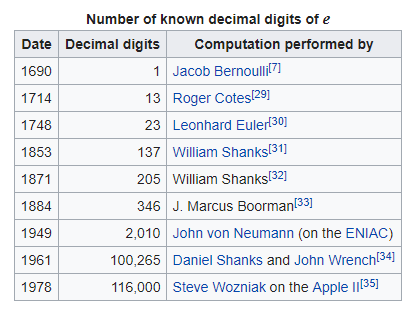
- Since 1978, people have calculated many more digits of e. For example, on January 3, 2019 (my birthday this year!) Gerald Hofmann reported 8,000,000,000,000 decimal digits of e. For a list of “Notable Large Computations” of e, see this page.
Now, back to sigmoid and softmax…
Sigmoid = Multi-Label Classification Problem = More than one right answer = Non-exclusive outputs (e.g. chest x-rays, hospital admission)
- When we’re building a classifier for a problem with more than one right answer, we apply a sigmoid function to each element of the raw output independently.
- The sigmoid function looks like this (notice the number e in there):
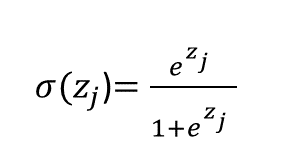
Here, the sigma symbol σ indicates the sigmoid function. The expression σ(zj) indicates that we are applying the sigmoid function to the number zj. (Apologies that I can’t do subscripts well in WordPress; the j in “zj” is supposed to be a subscript.) “zj” indicates a single raw output value, e.g. -0.5. What’s the j for? It tells us which of the output values we are using. If we have four output values, we have j = 1, 2, 3, or 4. In the previous example where our raw outputs were [-0.5, 1.2, -0.1, 2.4], we have z1 = -0.5, z2 = 1.2, z3 = -0.1, z4 = 2.4
Thus,

and so on for z2, z3, and z4.
Because we apply the sigmoid function to each raw output value separately, this means our network can output that all of the classes have low probability (e.g. “there are no abnormalities in this chest x-ray”), that one class has high probability but the other classes have low probability (e.g. “there is only pneumonia in the chest x-ray”), or that multiple or all classes have high probability (e.g. “there is pneumonia and an abscess in this chest x-ray.”)
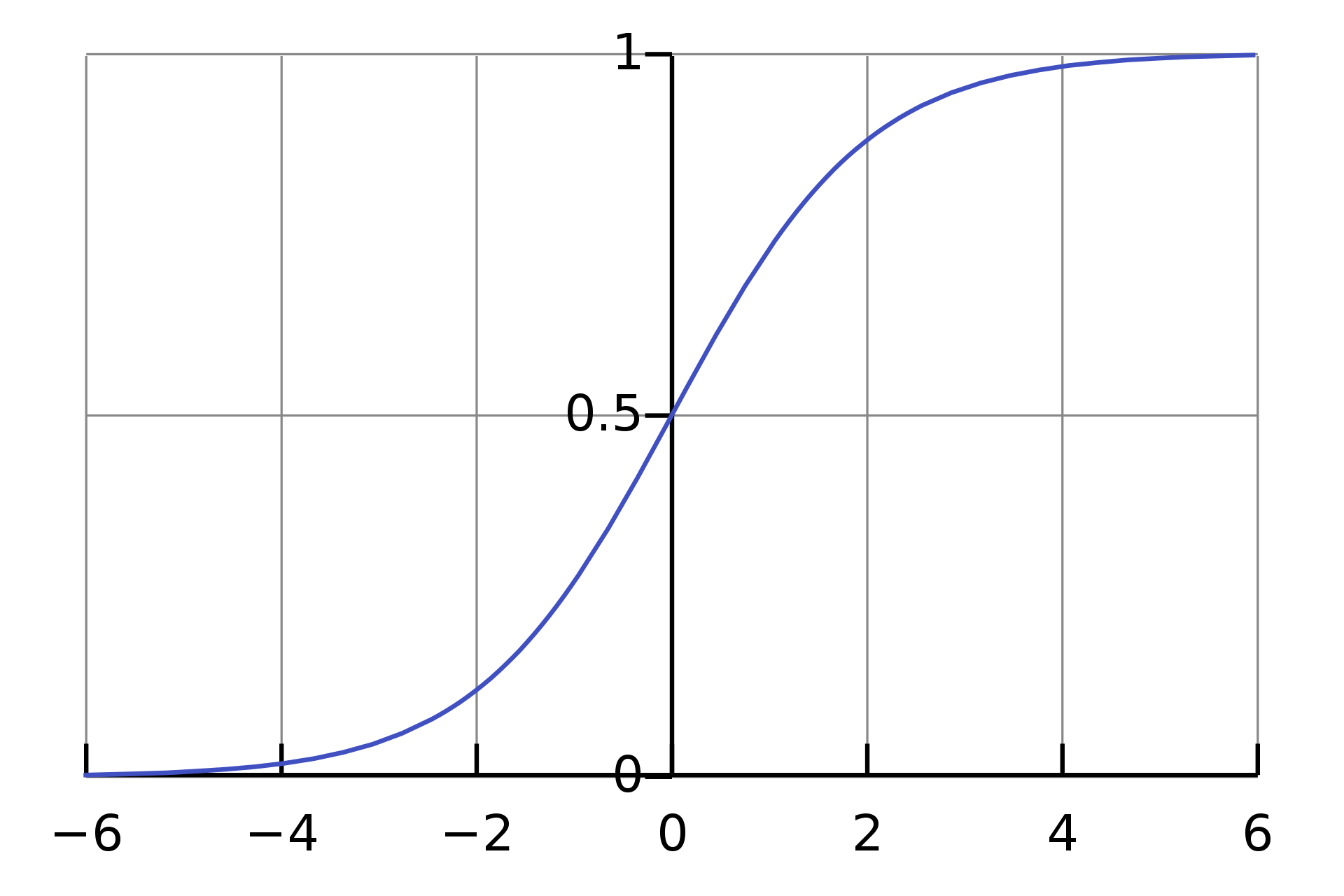
Here is a graph of the sigmoid function:
Softmax = Multi-Class Classification Problem = Only one right answer = Mutually exclusive outputs (e.g. handwritten digits, irises)
- When we’re building a classifier for problems with only one right answer, we apply a softmax to the raw outputs.
- Applying a softmax takes into account all of the elements of the raw output, in the denominator, which means that the different probabilities produced by the softmax function are interrelated.
- The softmax function looks like this:
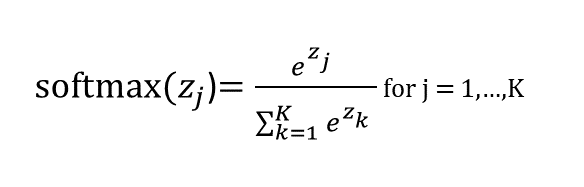
This is similar to the sigmoid function, except in the denominator we sum together e^thing for all of the things in our raw output. In other words, when calculating the value of softmax on a single raw output (e.g. z1) we can’t just look at z1 alone: we have to take into account z1, z2, z3, and z4 in the denominator, like this:
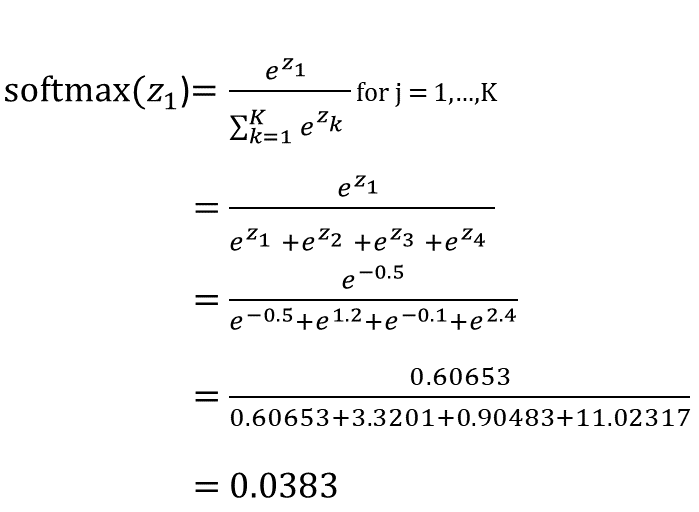
The softmax is cool because it ensures that the sum of all our output probabilities will be equal to one:
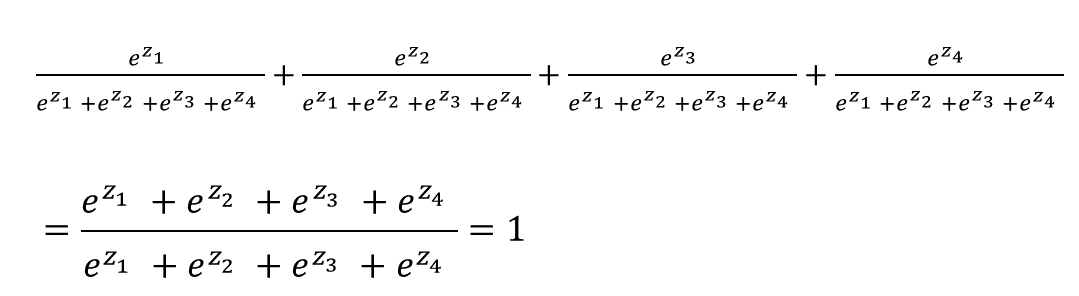
That means if we’re classifying handwritten digits and applying a softmax to our raw outputs, in order for the network to increase the probability that a particular example is classified as an “8” it needs to decrease the probabilities that the example is classified as some other number(s) (0, 1, 2, 3, 4, 5, 6, 7, and/or 9).
One more sigmoid and softmax calculation example

Summary
- If your model’s output classes are NOT mutually exclusive and you can choose many of them at the same time, use a sigmoid function on the network’s raw outputs.
- If your model’s output classes are mutually exclusive and you can only choose one, then use a softmax function on the network’s raw outputs.
About the Featured Image
The featured image is a painting by Carl Bloch titled “In a Roman Osteria.” An osteria is a type of Italian restaurant serving simple food and wine. I stumbled across this painting today on the interwebs and thought for a while about how I could make it the featured image of this post, because I think it’s an interesting painting. I finally came up with a connection between the painting and sigmoids/softmaxes: a visual mnemonic!
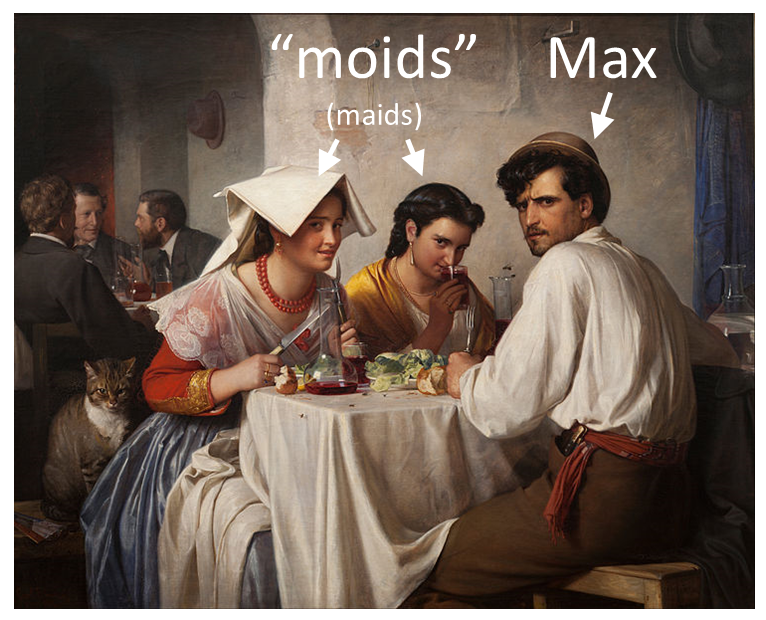
When you have multiple reasonable classifier outputs, use a “moid” (sigmoid – the two “moids”/”maids” on the left of the picture). When you have only one reasonable classifier output, use a “max” (softmax – I have named the frowning guy on the right “Max”).
The end!
References
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments are closed.