

This tutorial is based on my repository pytorch-computer-vision which contains PyTorch code for training and evaluating custom neural networks on custom data. By the end of this tutorial, you should be able to:
- Design custom 2D and 3D convolutional neural networks in PyTorch;
- Understand image dimensions, filter dimensions, and input dimensions;
- Understand how to choose kernel size, stride, and padding;
- Understand the basics of object-oriented programming relevant to PyTorch;
- Understand how to use nn.Sequential for better model organization.
Step 1: Download the code.
The repository with all the code is https://github.com/rachellea/pytorch-computer-vision
If you want to follow along with this tutorial and/or use the code, you should clone or download the repository. For more background on using Git see this post.
Step 2: Create the conda environment
Inside the repository there is a yml file, tutorial_environment.yml, that includes all the dependencies needed to run the tutorial code. To create the conda environment with all the dependencies,
(a) Install Anaconda. https://docs.anaconda.com/anaconda/install/
(b) Create the conda environment:
conda env create -f tutorial_environment.yml
Note that in the conda environment the Python version and package versions are not “bleeding edge” so that this environment should work on Linux, Mac, or Windows. For more background on Anaconda and why it’s useful for machine learning projects, see this post.
2D Convolutional Neural Networks (CNNs)
This post focuses on convolutional neural networks (CNNs), which are popular in computer vision tasks. For a 5-minute introduction to CNNs, see this post; for a longer introduction, see this post.
For many tasks, it is appropriate to use an existing CNN architecture such as a predefined ResNet. In other cases, you may want to modify an existing CNN, e.g. to add some custom convolutional layers after using a pre-trained convolutional feature extractor. Finally, perhaps you would like to write your own CNN entirely from scratch, without any pre-defined components. In this post you will learn how to build your own 2D and 3D CNNs in PyTorch.
Image Dimensions
A 2D CNN can be applied to a 2D grayscale or 2D color image. 2D images have 3 dimensions: [channels, height, width].
A grayscale image has 1 color channel, for different shades of gray. The dimensions of a grayscale image are [1, height, width].
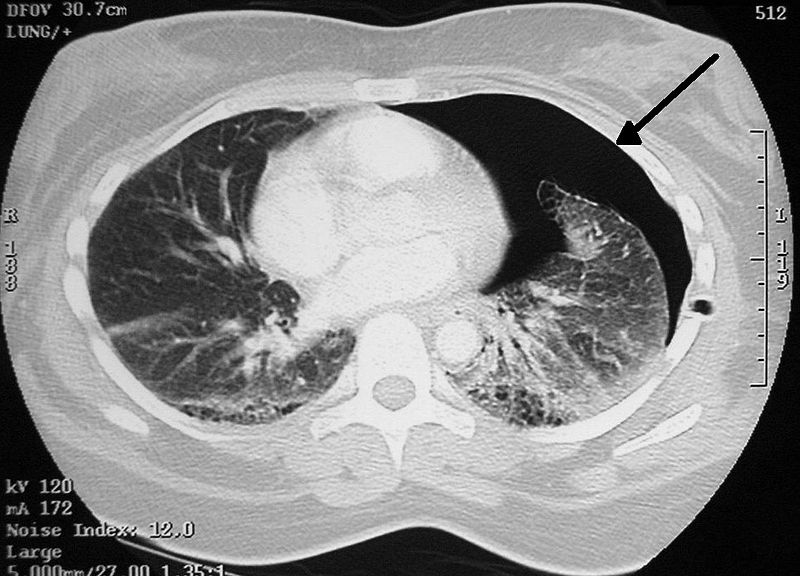
Chest CT scan showing pneumothorax. 2D grayscale image (1 color channel), e.g. dimensions [1,400,500]. Source: Wikipedia (license: CC)
A color image has 3 channels, for the colors red, green, and blue (RGB). Therefore, the dimensions of a color image are [3, height, width].

Samoyed on the beach. 2D color image (3 color channels), e.g. dimensions [3,400,500]. Source: Wikipedia (public domain)
Even though these “2D” images actually have three dimensions [channels, height, width] we still consider them “2D” because when they are displayed to people, only 2 spatial dimensions are explicitly shown.
Filter Dimensions
A “2D” CNN has 3D filters: [channels, height, width]. For an animation showing the 3D filters of a 2D CNN, see this link.
The input layer of a CNN that takes in grayscale images must specify 1 input channel, corresponding to the gray channel of the input grayscale image.
The input layer of a CNN that takes in color images must have 3 input channels, corresponding to the red-green-blue color channels of the input color image.
Overall Input Dimensions
Overall, a “2D” CNN has 4D input: [batch_size, channels, height, width]. The batch_size dimension indexes into the batch of examples. A batch is a subset of examples selected out of the whole data set. The model is trained on one batch at a time.
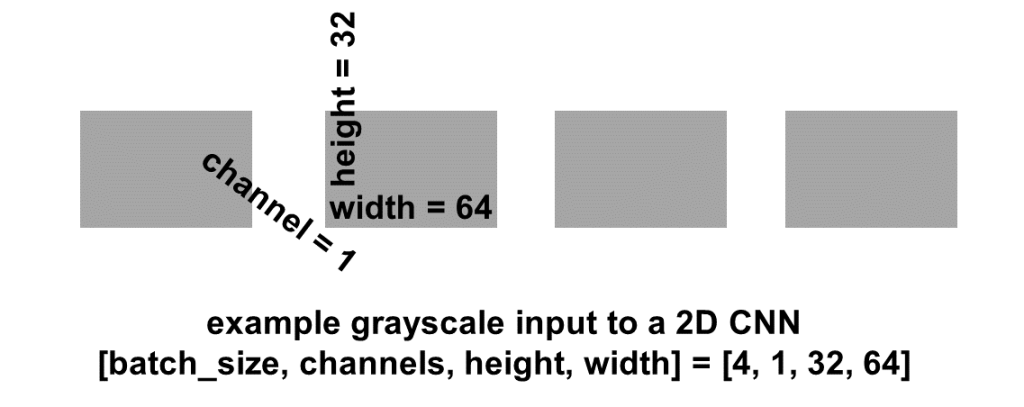
Example 4D input to a 2D CNN with grayscale images. Image by Author.
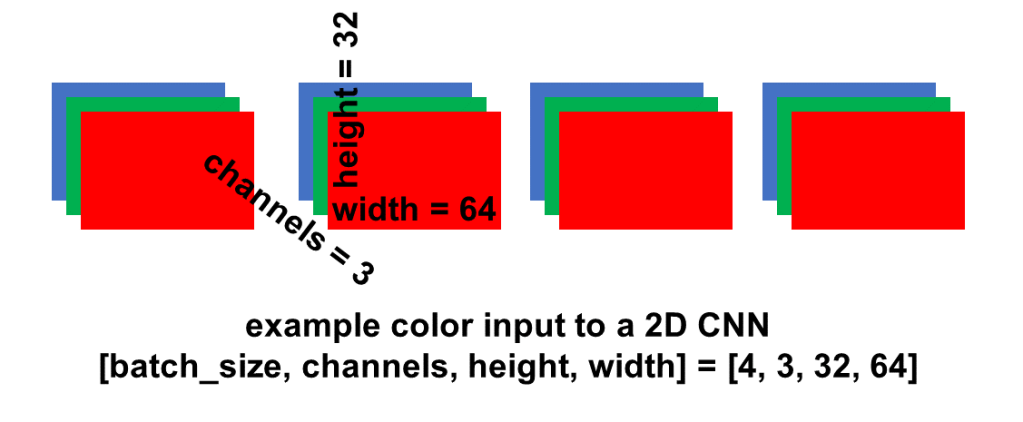
Example 4D input to a 2D CNN with color images. Image by Author.
Defining a 2D CNN Layer in PyTorch
In PyTorch the function for defining a 2D convolutional layer is nn.Conv2d. Here is an example layer definition:
nn.Conv2d(in_channels = 3, out_channels = 16, kernel_size = (3,3), stride=(3,3), padding=0)
In the above definition, we’re defining 3 input channels (for example, 3 input color channels). The out_channels can be thought of as the number of different patterns we want to detect in this layer. The number of out_channels of one CNN layer will become the number of in_channels of the next CNN layer.

Anatomy of a 2D CNN layer. Image by Author.
2D CNN Sketch with Code
Here is a sketch of a 2D CNN:

2D CNN sketch. Image by Author. Normal CT slice from Radiopedia
The PyTorch code for the 2 layers of this CNN that are shown is:
self.conv_two_layers = nn.Sequential(
nn.Conv2d(in_channels = 1, out_channels = 8,
kernel_size = (2,2), stride=(2,2), padding=0),
nn.Conv2d(in_channels = 8, out_channels = 16,
kernel_size = (2,2), stride=(2,2), padding = 0))
Notice how in this example our 1-channel grayscale input image was converted into a 8-channel intermediate representation, via processing by the first CNN layer. This 8-channel intermediate representation then became a 16-channel intermediate representation after processing by the second CNN layer.
The number of out_channels in one layer of a CNN determines the number of channels/features that will be present in that layer’s output.
Kernel Size (Filter Size)
In a CNN, a kernel (filter) slides across the image and detects certain patterns in the image. The patterns that the kernel detects depend on the kernel’s weights. The kernel’s weights, in turn, are learned during training.
The kernel size in a 2D CNN is specified by height and width. Here is a visualization of a few different kernel_size options. (Note that the actual numerical values of the kernel elements are unlikely to be as large as the values shown here, and they definitely won’t be exact integers – these numbers are just shown to emphasize that the kernel is an organized collection of numbers):
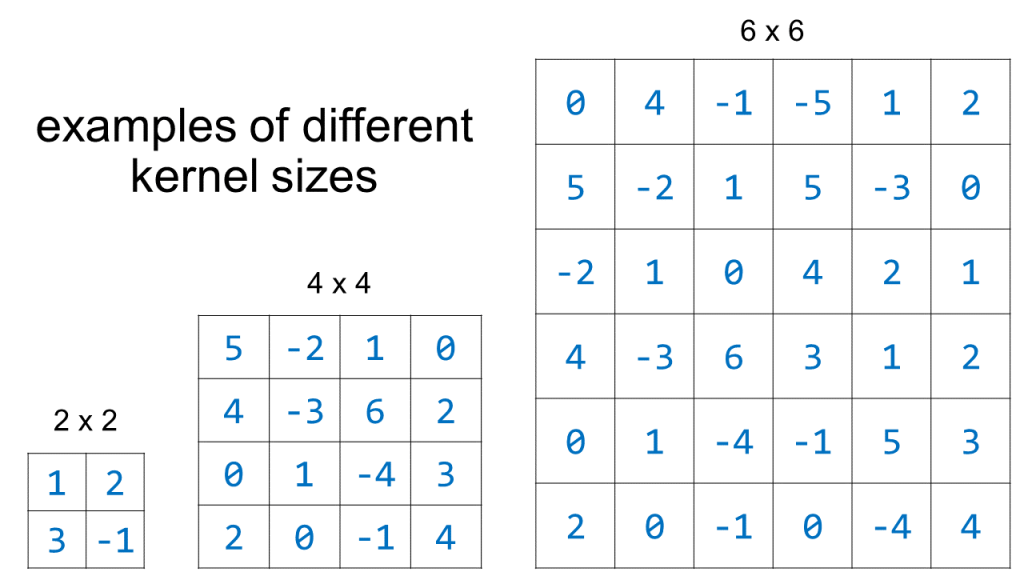
Examples of different kernel sizes. Image by Author.
The ResNet is a popular kind of pre-defined CNN architecture. In the ResNet paper, they summarize a few ResNet architectures:
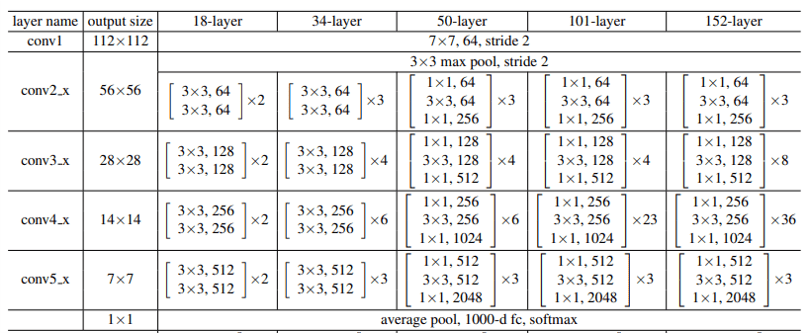
This table shows the definitions of the CNN architectures for several ResNets: ResNet-18 (“18-layer”), ResNet-34 (“34-layer”), ResNet-50 (“50-layer”), ResNet-101 (“101-layer”), and ResNet-152 (“152-layer). You can see from the table contents that 3×3 is a popular kernel size.
1×1 Kernels / 1×1 Convolution
You can also see from this table that 1×1 kernels are sometimes used. At first glance, a 1×1 convolution might seem useless – what is the point of considering only 1 element at a time?
The key here is to remember that kernels are actually three-dimensional. You specify the desired height and width when you’re writing code, but the actual kernel that’s produced will also cover the entire channel dimension. In almost every circumstance, there will be more than one channel, and therefore even a 1×1 kernel will cover more than one number. For example, applying a 1×1 convolutional kernel to a representation with 16 channels, 32 height, and 32 width will produce an output representation with 1 channel, 32 height, and 32 width.
(One situation where only 1 channel is present is for an input grayscale image; however, here you wouldn’t apply a 1×1 kernel because it wouldn’t make sense.)
Here is a visualization of a 2×2 kernel vs. a 1×1 kernel applied to a representation with 8 channels:
Image by Author
We can see from this figure that even the 1×1 kernel is computing over multiple numbers – in this example, it covers 8 numbers, one number from each of the 8 channels.
The overall size of the 2×2 kernel is actually 2 x 2 x 8 = 32.
The overall size of the 1×1 kernel is actually 1 x 1 x 8 = 8.
What is the point of using a 1×1 convolution? The point is to combine information across different channels/features, without collapsing the spatial dimensions at all.
Strides and Padding
The “stride” is the “step size” of the kernel – how far it moves between computations. A bigger stride results in a smaller size of the output map.
The padding refers to additional numbers, often zeros, that are concatenated to the border of the representation. Reasons that padding may be used include:
- By default, pixels on the edge of the input only ever interact with the edge of the kernel. If we want each edge pixel to have the chance to interact with any other part of the kernel, we need to use padding.
- By default, without padding the representation will get spatially smaller because the kernel always stays within the boundaries of the input (see the GIFs below). If we use padding, we have the option of preserving the spatial size throughout the CNN.
Note that padding is not strictly necessary, and many CNNs work fine without padding.
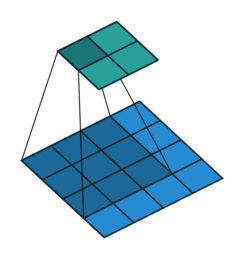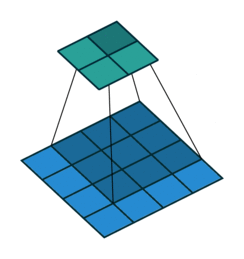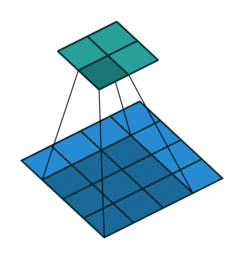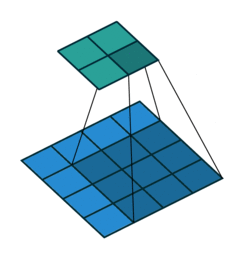
vdumoulin/conv_arithmetic has some great visualizations of stride and padding. In these visualizations, the blue maps are the inputs, and the cyan maps are the outputs. A few of the visualizations are shown here:
No padding, no strides. You can see from this visualization how without padding, the cyan output is smaller than the blue input, because the filter doesn’t go outside the border of the input. Also note that “no strides” is the same as “stride of 1” i.e. a step size of 1 pixel at a time:
No padding, yes strides. Strides means the filter “jumps” a pre-specified number of pixels at a time. Here there is a stride of 2, so the filter jumps over 2 pixels:
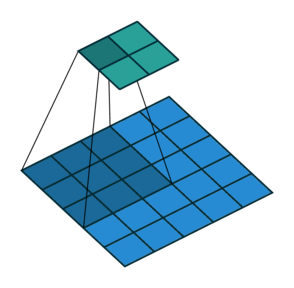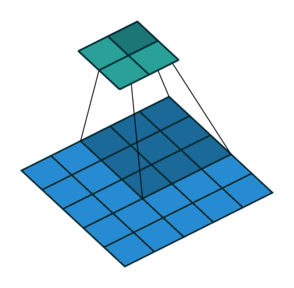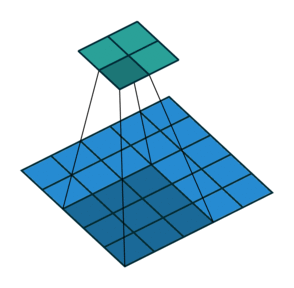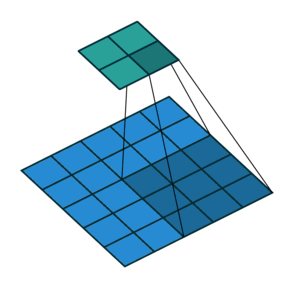
Yes padding, no strides. You can see that here, a lot of padding has been added. In fact, so much padding has been added that the cyan output is even BIGGER than the blue input. This is a rather extreme amount of padding and is not often used in practice, but it’s good for illustration:
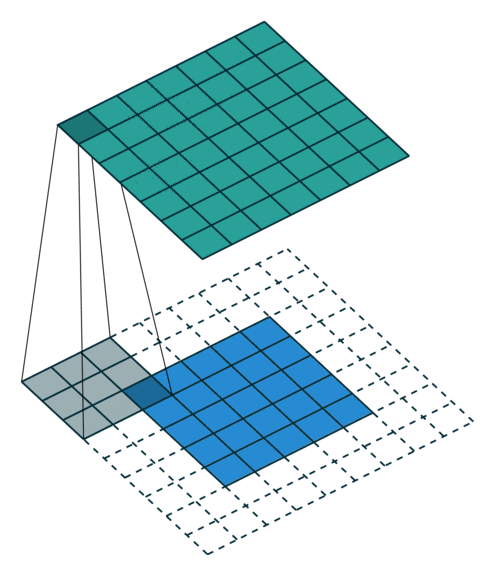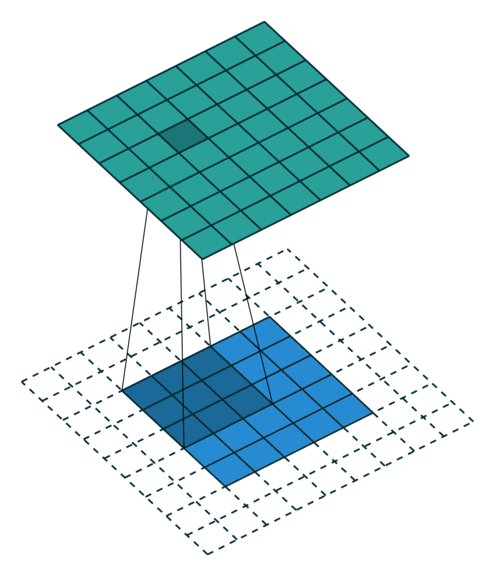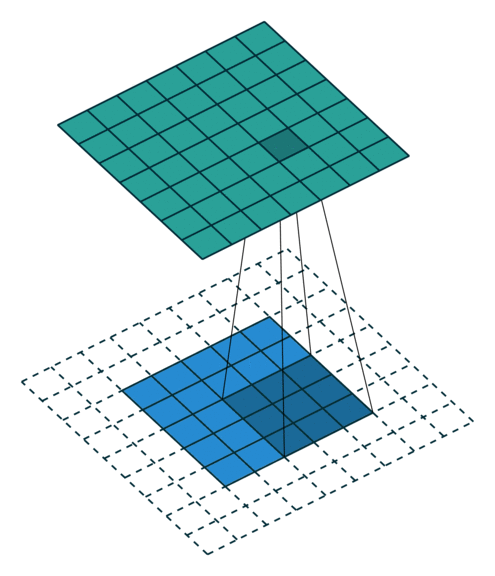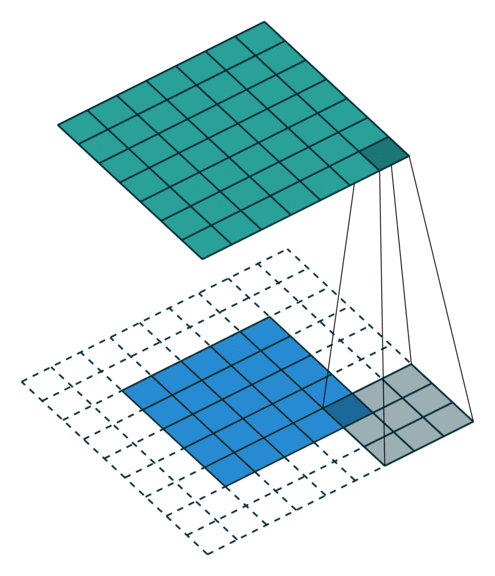
Yes padding, yes strides. In this example, both padding and strides are used.
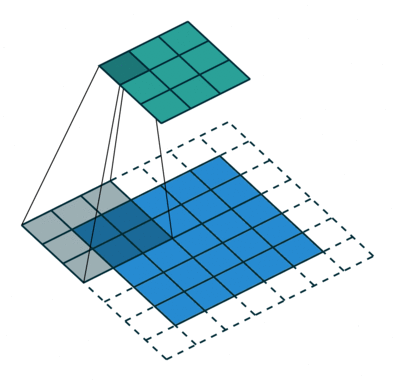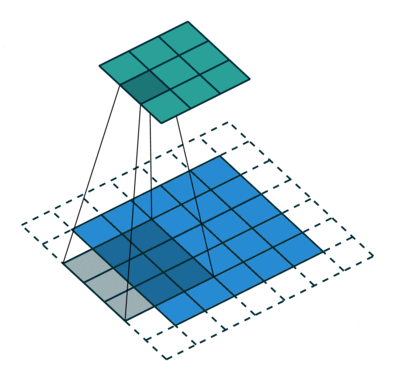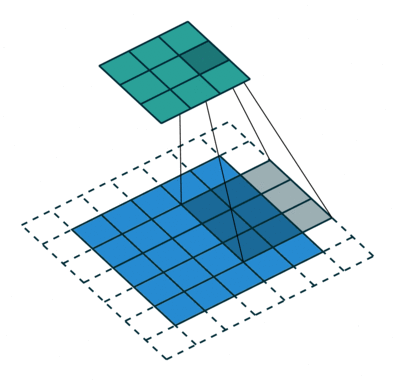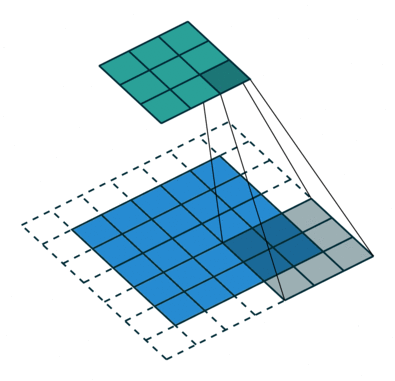
The 4 GIFs above are copyright (c) 2016 by vdumoulin and available under the MIT License (free to use, copy, publish, and distribute). Please visit vdumoulin/conv_arithmetic for additional animations of padding, strides, transposed convolution, and dilated convolution.
Choosing Kernel Size, Strides, and Padding
Frequently the kernel size and the stride are chosen to be the same, e.g.
- kernel_size=(1,1) and stride=(1,1)
- kernel_size=(2,2) and stride=(2,2)
- kernel_size=(3,3) and stride=(3,3)
However, the kernel size and stride do NOT have to be the same, nor does the kernel size have to be so small. As an example, GoogLeNet includes layers with the following combinations (see this paper, Table 1):
- kernel_size=(7,7) and stride=(2,2)
- kernel_size=(3,3) and stride=(2,2)
- kernel_size=(3,3) and stride=(1,1)
- kernel_size=(7,7) and stride=(1,1)
Popular kernel sizes include (3,3), (5,5) and sometimes (7,7).
The default padding in PyTorch is 0, i.e. no padding.
For an additional perspective on kernel size, stride, and padding, see “A Gentle Introduction to Padding and Stride for Convolutional Neural Networks.”
3D Convolutional Neural Networks
Image Dimensions
A 3D CNN can be applied to a 3D image. There are many different kinds of 3D images, including videos and medical images like CT scans or MRIs. 3D images have 4 dimensions: [channels, height, width, depth].

Vide of dog galloping. From Wikipedia (public domain). This grayscale video has 1 channel for color, 2 spatial dimensions (height x width), and 1 time dimension, for a total of 4 dimensions.

Video of an ornithopter. From Wikipedia (public domain). This color video has 3 channels for color, 2 spatial dimensions (height x width), and 1 time dimension, for a total of 4 dimensions.

CT scan volumetric image. From Wikipedia (Creative Commons license). The CT scan has been “unstacked” so that it is possible to appreciate all 3 spatial dimensions at once. This CT has 1 channel for color (gray), and 3 spatial dimensions (height x width x depth).
Filter Dimensions
A 3D CNN filter has 4 dimensions: [channels, height, width, depth].
Overall Input Dimensions
A 3D CNN has 5 dimensional input: [batch_size, channels, height, width, depth].
Defining a 3D CNN Layer in PyTorch
The function to define a 3D CNN layer in PyTorch is nn.Conv3d. Example:
nn.Conv3d(in_channels = 3, out_channels = 16, kernel_size = (3,3,3), stride=(3,3,3), padding=0)
Notice that this is pretty much the same as defining a 2D CNN layer, except that we can define 3 dimensions for the kernel and 3 dimensions for the stride.
Note that none of these dimensions are required to be the same – we could define a kernel_size of (1,2,5) and a stride of (2,4,3) if we wanted to (although it would be hard to think of a reason for choosing such random-seeming kernel size and stride numbers).
As with 2D CNNs, frequently the kernel_size and stride are chosen to be the same in 3D CNNs.
Here is an illustration showing the 4D filters of a 3D CNN. This is for an example in which the input was a medical image, and we’ve extracted 512 different features, where each feature’s dimensions correspond to the 3D dimensions of the input (right/left, front/back, and up/down=neck/chest/abdomen):

Image by Author
Structure of a Full 2D CNN in PyTorch
Here is a fully functional, tiny custom 2D CNN in PyTorch that you can use as a starting point for your own custom CNNs:

Image by Author
This code is available here. All model definitions are found in models/custom_models_base.py. The file models/components.py includes model components. (It is often convenient to store pieces of networks that are re-used in a separate module. For example, if you have a group of convolutional layers that you want to use in many different models, you can store that group of layers in components.py.)
Object-Oriented Programming for PyTorch Models
If you aren’t an expert in object-oriented programming, don’t worry – you don’t need to know a whole lot about it in order to get started building your own CNNs in PyTorch. This section covers everything you need to know about object-oriented programming to successfully build your own CNN.
First let’s take a look at the methods inside of TinyConv. To define a CNN in PyTorch, you need at least two methods: one is called __init__() and the other is called forward().
__init__() defines the layers of the model. The layers technically don’t have to be defined in any particular order, but it’s visually nicest if they are defined in the order that they are used.
forward() defines how your model should compute on an input x. Notice that we’ve passed x to forward, as forward(self, x). As mentioned in earlier sections, the input “x” is 4-dimensional for a 2D CNN [batch_size, channels, height, width], and 5-dimensional for a 3D CNN [batch_size, channels, height, width, depth].
Classes and Objects
This figure summarizes classes, objects, and attributes:

Image by Author
Every CNN in PyTorch is defined using a “class” — hence the top line of code that defines “class TinyConv(nn.Module)”.
The word “method” just means “function defined inside of a class.”
TinyConv is the name of the class. The class can be named whatever you want – even SuperAwesomeModelThatSolvesEverything.
If we use the class to make an instance of a model that we’re actually going to use for training, validation, and testing, e.g. by running this line of code:
mymodel=TinyConv()
then that instance “mymodel” is called an “object.” An “object” is an instance of a class.
Attributes
Inside the __init__() method of TinyConv, we’ve defined self.conv and self.fc. These attributes define the layers that make up our model.
The word “self” enables these attributes to be accessed anywhere within TinyConv without explicitly passing them in as arguments. You need to use “self” in a few places:
- As an argument to all the methods: __init__(self) and forward(self, x)
- When defining all the attributes: e.g. self.conv = something
- When you use any attribute, e.g. x = self.conv(x)
One advantage of object-oriented programming is that you don’t have to pass around as much “stuff” as parameters, because we can use the attributes directly.
Inheritance
You’ll notice by looking at the top line, class TinyConv(nn.Module) that we’re making use of “nn.Module.” What is nn.Module?
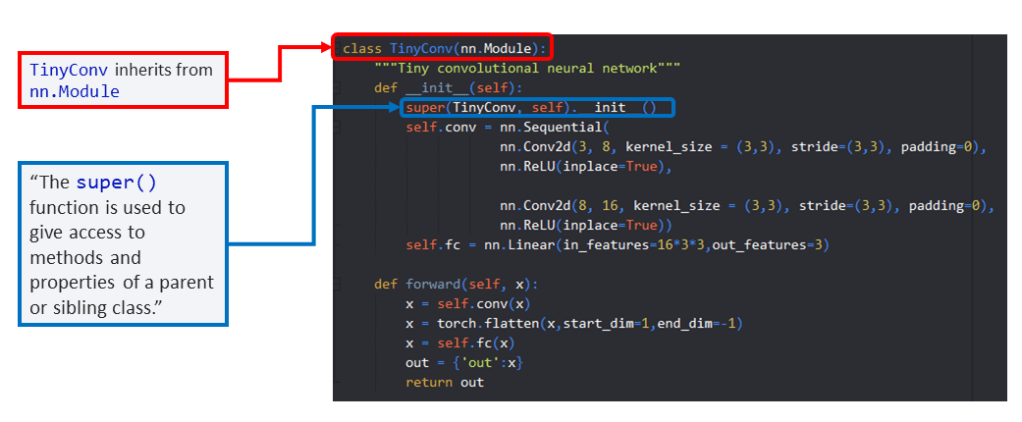
Image by Author
nn.Module is the “base class” for all neural networks in PyTorch. You can read more about it here, in the PyTorch documentation. In brief, nn.Module provides a ton of functionality to your custom model, including allowing your model to keep track of its trainable parameters and allowing you to switch your model between the CPU and the GPU.
You don’t need to worry about reading through all the code that is part of nn.Module. All you need to do is make sure that your custom model “inherits” from nn.Module. When your model “inherits” from nn.Module, your model will gain all the functionality that nn.Module provides.
Inheritance is as easy as sticking nn.Module inside the parentheses after the name of your class as shown in the TinyConv example.
class TinyConv() does NOT inherit from nn.Module, and won’t work.
class TinyConv(nn.Module) does inherit from nn.Module and will work.
The one other piece you need in order to make inheritance work properly is this line:
super(TinyConv, self).__init__()
where you replace “TinyConv” with whatever name you decided to give your custom model.
For more details about what super() is doing, you can see these references: ref1, ref2, ref3
Organizing Your Model with nn.Sequential
You’ll notice that within TinyConv, we’ve made use of something called nn.Sequential. nn.Sequential is provided by PyTorch to help with organizing layers of a neural network. Here is the same TinyConv network, defined with and without the use of nn.Sequential:
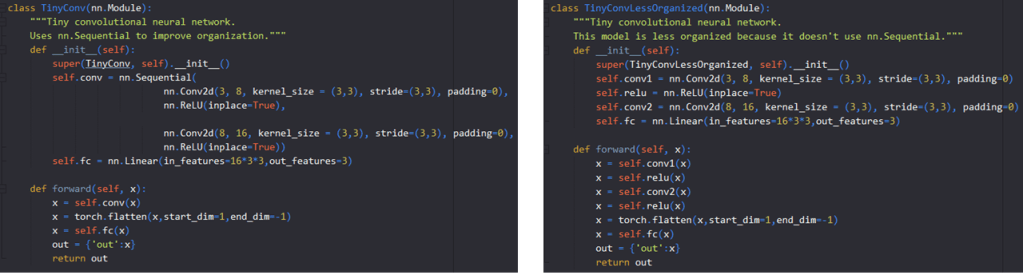
You can also view this code for TinyConv and TinyConvLessOrganized here.
Technically, nn.Sequential does not HAVE to be used – but it’s better to use it, because it helps keep the code more organized.
Code Demos: Tiny CNNs on Tiny Data (runs on CPU)
You can run several demos of custom CNNs using the code in this repository. To run the demos all you need to do is update the paths within the demo files to specify where you want results and data to be stored.
Demo 1 will train and evaluate a tiny CNN on tiny data, specifically the CNN “TinyConvWithoutSequential” which is the model shown above where nn.Sequential is not used. Note that this CNN and data set are extremely small, so you should be able to run Demo 1 on any computer, including a small laptop with a small CPU and no GPU.
To run Demo 1, update the results path in the Demo-1-TinyConvWithoutSequential-TinyData.py and then run the following command in an interpreter with the conda environment described at the beginning of this blog post:
python Demo-1-TinyConvWithoutSequential-TinyData.py
Demo 2 will train and evaluate a tiny CNN on tiny data, specifically the model “TinyConv,” which is shown above and does make use of nn.Sequential.
Here’s how to run Demo 2:
python Demo-2-TinyConv-TinyData.py
If you take a look at the demo code, you can see that the model being used and the dataset being used are defined as part of the demo configuration. This means you can easily swap in your own model and your own data set, and use this code to train, evaluate, and test on a problem of interest to you.
Code Demos: Larger CNNs on Larger Data (needs GPU)
Demo 3 will train and evaluate a CNN on the PASCAL VOC 2012 dataset of natural images using a model with a VGG-16 feature extractor pre-trained on ImageNet. To run this demo, you should probably use a GPU.
python Demo-3-VGG16-PASCAL.py
Finally, Demo 4 will train and evaluate a few different CNN variants on the PASCAL VOC 2012 data using a model with a VGG-16 feature extractor. The different CNNs have slightly different layers after the VGG feature extractor. Some of the CNNs use a feature extractor pretrained on ImageNet and others use a feature extractor that is randomly initialized.
python Demo-4-VGG16Customizable-PASCAL.py
Note that in order to run Demo 3 or Demo 4, you will need to uncomment some code in the demo files to download the PASCAL VOC 2012 data set. Once the data is downloaded, you can re-comment those lines of code and run the demo.
Train, Eval, and Test with src/run_experiment.py
The module src/run_experiment.py includes all the core code for actually running the experiments. run_experiment.py provides a class to train, evaluate, and test different models. You can pass in any data set, and you can pass in any model that is trained with a multilabel classification cross entropy loss. (If you take a look at the code, it is also straightforward to swap out the cross entropy loss for any kind of loss you want.) run_experiment.py also includes functionality to re-start a model that has crashed, code for early stopping, and calculation of the performance metrics AUROC and average precision (via importing evaluate.py).
A few key parts of run_experiment.py include these methods:
- run_model (line 166)
- train (line 206)
- valid (line 213)
- test (line 243)
- iterate_through_batches (line 258)
run_model() initializes the model (line 167), initializes the optimizer (line 172), and then carries out whatever task was specified – “train_eval” (train on the training set and evaluate on the validation set), “restart_train_eval” (re-start training/validation after a model crash), “predict_on_valid” (make predictions on the validation set), or “predict_on_test” (make predictions on the test set, which should only be done after model development is complete).
train() puts the model in “training mode” (line 207), then does the actual training by calling iterate_through_batches. It also calls functions to save the value of the loss for logging purposes, and plot performance metrics (line 210).
valid() is similar to train() except that it specifies that the model should be in evaluation mode (line 214) and also makes sure that no gradients will be calculated (line 215). It additionally performs an early stopping check. Early stopping is a technique in which training is stopped on the basis of the performance on the validation set. You can read more about early stopping here.
test() will load in a saved model and use that saved model to make predictions on the test set and calculate test set performance.
Finally, iterate_through_batches() provides the meat of the training, validation, and testing process – it enables iterating through the data set and feeding data to the model. During training, the predictions on the data will be compared to the ground truth in order to update the model’s parameters. During validation and testing, the model will be used to make predictions on validation or test data.
Within iterate_through_batches(), we store the predicted probabilities and ground truth of every batch, so that at the end of an epoch (i.e., when we’ve gone through all the batches of the data set) we can calculate overall performance metrics for the whole epoch. A critical tip is to only ever use pre-allocated numpy arrays for storing the predicted probabilities and ground truth across batches. Using pre-allocated arrays (lines 263-266) enables better memory usage. I have empirically found that using numpy array concatenation (instead of pre-allocated numpy arrays) causes crazy memory fragmentation and slows down training, particularly when the batch size is small. Concatenation really shouldn’t be as much of an issue as it actually is, if the Python garbage collector properly took care of getting rid of old numpy arrays…But in any case, I’ve seen memory issues from concatenation happen in a few different settings and that is why I now always use pre-allocated numpy arrays to store predictions and ground truth across batches.
Tips for Building Custom CNNs
- If you are building a classification CNN, usually you will get better performance or at least faster convergence if you use a pre-trained convolutional feature extractor, rather than a CNN built entirely from scratch. You can use a pre-trained feature extractor followed by custom layers, as shown in the example model VGG16Customizable.
- The number of filters you want to use in one layer is conceptually like the number of “patterns” you want to detect in that layer.
- The number of filters in a layer is defined as the number of out_channels of that layer.
- The number of in_channels for a layer is equal to (a) the number of channels in the input image, if it’s the first layer, or (b) for later layers in the CNN, the number of in_channels for a layer is equal to the number of out_channels of the previous layer.
Tips for Transitioning from Convolutional Layers to Fully Connected Layers
- If you want to transition from a convolutional layer to a fully connected layer, you need to flatten the representation first: [batch_size, channels, height, width] must become [batch_size, channels*height*width]. For example, [batch_size, 64, 4, 4] must become [batch_size, 1024]. An example of this flattening step is shown in line 128 here via the line x = torch.flatten(x,start_dim=1,end_dim=-1).
- Note that the input dimension of the fully connected layer needs to equal the actual size of the input data that you’re going to be feeding to that fully connected layer. You can calculate this input dimension on the basis of the output of the preceding convolutional layer, which will require a bit of arithmetic to figure out what that convolutional layer’s output shape should be based on all the preceding layers. Or if you want to save time and skip the arithmetic you can just specify some arbitrary dimension for the fully connected layer input, let the model crash, and then inspect the actual shape of the output of the flattening step to know what shape you need as the input shape of the fully connected layer (this works best while using pdb, the Python debugger).
- Be careful with transitioning from convolutional layers to fully connected layers. You can easily run out of memory if you try to specify a fully connected layer that is too large. If you need to cut down the size of the input to your fully connected layer, you can try (a) reducing the number of channels of the preceding convolutional layer either by specifying a smaller number of out_channels or by using a subsequent 1×1 convolution, (b) increasing the filter size and stride of the preceding convolutional layer, (c) adding a pooling operation like adaptive average pooling or max pooling, or simply (d) adding a few more convolutional layers with no padding to make the representation smaller.
Checklist for Building Custom CNNs
- Did you choose the right number of in_channels in your first layer? (1 for grayscale input, 3 for color input)
- Did you ensure that the in_channels of a particular convolutional layer are equal to the out_channels of the preceding convolutional layer?
- Did you remember to define both an __init__() and a forward() method in your CNN model definition?
- Did you remember to specify “self” as a parameter of the __init__() and forward() methods?
- Did you remember to use “self” before the names of any attributes defined in __init__() that you wish to use within the forward() method? e.g. self.conv2d, self.fc, self.first_conv, self.classifier…
- Did you remember to return something from the forward() method, so that your model actually sends out its final predictions?
- Did you remember to inherit from nn.Module by using the syntax “class NameOfModel(nn.Module)” when defining your model?
- Did you remember to update the line super(NameOfModel, self)._init_() with the actual name of your model, so that inheritance works properly? If this super line doesn’t match the name you chose when defining the class, you’ll run in to an error.
Summary
PyTorch gives you the freedom to define any CNN model you’d like. In this tutorial, we’ve introduced the pytorch-computer-vision repository for training, validating, and testing any custom CNN on any data set. We’ve overviewed image/kernel/input dimensions, CNN structure, kernel size, stride, padding, a little object-oriented programming, and the key components of a PyTorch CNN model definition.
Happy modeling!
Featured Image
The featured image is of a library, and is from Wikipedia (Creative Commons license).
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments are closed.