

This post addresses the appropriate way to split data into a training set, validation set, and test set, and how to use each of these sets to their maximum potential. It also discusses concepts specific to medical data with the motivation that the basic unit of medical data is the patient, not the example.
The Basics
If you are already familiar with the philosophy behind splitting a data set into training, validation, and test sets, feel free to skip this section. Otherwise, here’s how and why we split data in machine learning.
A data set for supervised learning is composed of examples. Depending on the task, one example may be one image, one video, one sentence, one block of text, or one audio recording. Each example is paired with a label, for example, a category like “cat” or “dog.”
At the beginning of a project, a data scientist divides up all the examples into three subsets: the training set, the validation set, and the test set. Common ratios used are:
- 70% train, 15% val, 15% test
- 80% train, 10% val, 10% test
- 60% train, 20% val, 20% test
(See below for more comments on these ratios.)
The three sets are then used as follows:
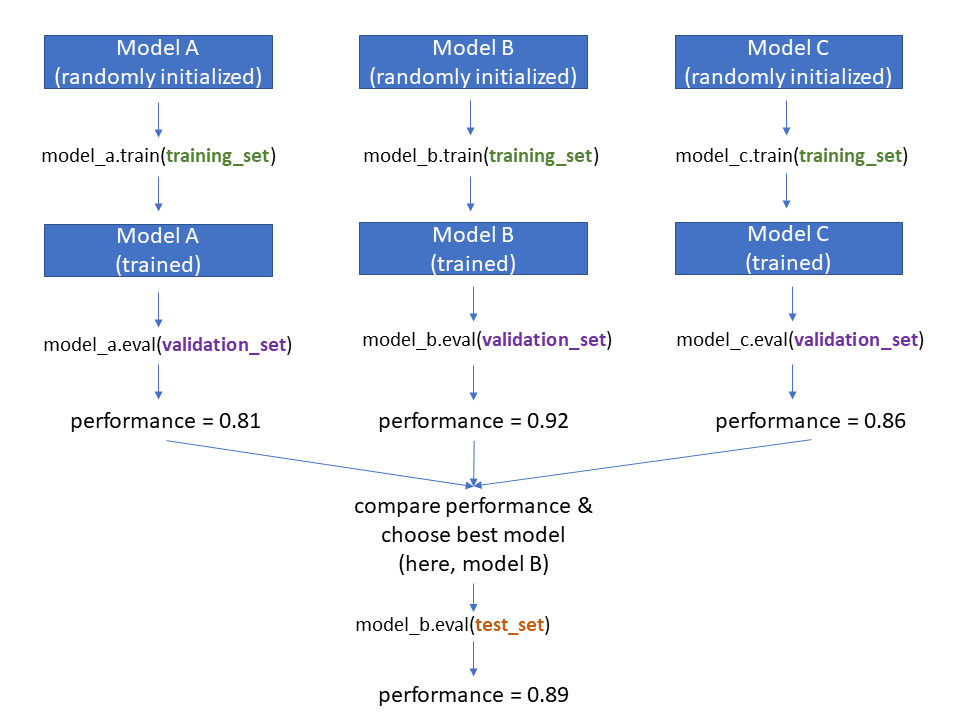
As shown in the figure, let’s imagine you have three models to consider: Model A, Model B, and Model C. These could be different architectures (like ResNet vs VGG vs AlexNet), or they could be different variations of the same model (like ResNet with three different learning rates.) The steps are as follows:
- Randomly initialize each model
- Train each model on the training set
- Evaluate each trained model’s performance on the validation set
- Choose the model with the best validation set performance
- Evaluate this chosen model on the test set
Why can’t we just use one data set? Let’s imagine what would happen if we used ALL our data as a “training set.” When we wanted to evaluate performance, we’d just look at the training set performance. Now, if we get lucky, the training set performance might be reflective of how the model would perform on data it has never seen before. But if we get unlucky, the model has simply memorized the training data examples and when we feed it an example it’s never seen before, it completely fails (“overfitting“). We have no way of figuring out whether we’re lucky or unlucky – which is exactly why we need a validation set. The validation set consists of examples the model has never seen in training, so if we get good validation set performance, we can be encouraged that our model has learned useful generalizable principles.
But, if we have a training set and a validation set, why do we also need a test set? The test set is important because the step of “choosing the best model” (based on validation performance) can cause a form of overfitting. Think about it this way: let’s say you tried a THOUSAND different models or model variations on your data, and you have validation set performance for all of them. The act of choosing the model with the best validation set performance inherently means that you, the human, have “tuned” the model details for the validation set. The performance value you see for the validation set on “the best model on the validation set” is inherently inflated. To get a non-inflated and more reliable estimate of how well this “best model” will do on data it’s never seen before, we need to use more data it’s never seen before! This is the test set. The test set performance will typically be slightly lower than the validation set performance.
Let’s go back now and address the choice of how much data to allocate for training, validation, and testing. Many people wonder what is the “right ratio” — but unfortunately, there are no clear rules about what ratio to use. Personally I like 70-15-15, but this is a subjective choice. The tradeoffs are as follows:
- More training data is nice because it means your model sees more examples and thus hopefully finds a better solution. If you have a tiny training data set your model won’t be able to learn general principles and will have bad validation / test set performance (in other words, it won’t work.)
- More validation data is nice because it helps you make a better decision about which model is “The Best.” If you don’t have enough validation data, then there will be a lot of noise in your estimate of which model is “The Best” and you might not make a good choice.
- More test data is nice because it gives you a better sense of how well your model generalizes to unseen data. If you don’t have enough test data, your final assessment of the model’s generalization ability might not be accurate.
Unfortunately, any data that you add to one set has to be taken away from another set. This is why for very small data sets, you probably want to use a technique like cross-validation (which is not covered in this post, but if you want to read more about it, you can check out this article.)
Appropriate Use of Train/Validation/Test Data
The key takeaway of this section is the following: YOTO (You Only use the Test set ONCE.)
I won’t mince words…If a data scientist wants to develop a new model to solve a problem, and they check the test set performance of a ton of different models and then report the test set performance of the best one, that’s cheating. They’ve overfit to the test set by virtue of checking performance on the test set repeatedly. The test set performance metric is no longer a trustworthy indicator of the model’s generalization ability.
Now, what is a good way to use the test set? Before we get to that, we’ll first discuss a good way to use the validation set.
The validation set is what you should use for every decision about model architecture and hyperparameters. If you are using a neural network model, for example, it is appropriate to use the validation set to:
- Choose the number of layers (depth);
- Choose the number of neurons per layer (width);
- Choose the number/shape of kernels in a CNN at each layer;
- Choose whether to use residual connections and where;
- Choose whether to use a pretrained feature extractor; choose which feature extractor to use; choose whether to fix or refine the weights of that feature extractor;
- Choose an activation function: ReLU, Leaky ReLU, ELU, etc.;
- Choose whether to use dropout; choose where in the model to use dropout; choose the dropout probability;
- Choose whether to use normalization and where: batch normalization, weight normalization, layer normalization, etc.;
- Choose an optimizer: Adam, Adagrad, SGD, etc.;
- Choose a learning rate;
- Choose a loss function: cross-entropy, MSE, custom loss for your application, etc.;
- Choose a batch size;
- Choose whether to use regularization; choose the regularization strength.
In other words, pretty much all the work you do on your machine learning project should use only the training set and the validation set. You should pretend that the test set does not exist.
Side note on architecture/hyperparameter optimization: It’s unrealistic to assume you’ll have the computational resources needed to optimize every single possible combination of every model characteristic in the list above. However, chances are you will explore at least a few of them in depth. If you’re interested in a discussion of hyperparameter optimization strategies, you can see this article. If you have 100 GPUs at your disposal, you’ll obviously be able to do a lot more hyperparameter optimization than if you have access to only 1 GPU.
Once you have decided on one best model – the Most Awesome Model Ever – based on a zillion experiments on your validation data set, it is time to use the test set. You should run your Most Awesome Model Ever on the test set to see its performance, once. That is the performance of your model that you should report.
In many papers it is common to compare the test set performance of Your Most Awesome Model Ever with the test set performance of Some Other Less-Awesome Models. In this case, practically speaking, you have to get the test set performance on Some Other Less-Awesome Models…Which is a limitation of the current “train-val-test” split approach. The readers of your paper will mentally be using the test set for model selection. (But, it is still way better than if you were to develop Your Most Awesome Model Ever using the test set, which is cheating.)
Medical Data Considerations
Using the test set only once to measure the performance of Your Most Awesome Model Ever is especially important if you are working on a medical data set, since medical data is almost always difficult to acquire and difficult to clean. You aren’t going to be able to get “another test set” easily, so you want the test set that you have to be used once so that it provides the best possible estimate of the model’s generalization ability. This becomes even more critical if you plan to deploy your model in a real-world setting. You don’t want to be claiming that your “heart disease risk model” has an AUROC of 0.95 on the test set when you’ve actually overfit to the test set and the true performance is more like 0.62…Because then you’ll be using a bad model and giving real patients misleading estimates of their heart disease risk.
Due to occasional abuse of test sets, some authors describing machine learning models on medical data have begun explicitly emphasizing that they used their test set appropriately. For example, in “An explainable deep-learning algorithm for the detection of acute intracranial haemorrhage from small datasets,” Lee et al. note,
To evaluate the performance of the model, two separate test datasets were collected retrospectively and prospectively after completion of the model development process.
In other words, Lee et al. didn’t even create a test set until after they were done developing a model using the training and validation data sets.
Here’s another example. In “End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography,” Ardila et al. use more than one test set, and they note,
Both test sets were run only once to avoid influencing model development. Additionally, all individuals who worked on modeling and image analysis were blinded to the diagnoses in the test set.
Creating Train/Validation/Test Splits for Medical Data
Medical data is different than other kinds of data because the splits must be determined by the patient, and not by the individual example. This applies whether you are working with medical images, medical text, or medical tabular data. Examples:
- Image Task: classify diseases in chest x-rays. In most chest x-ray data sets, the same patient has contributed multiple chest x-rays. The data must be split based on patient identifier rather than individual chest x-ray, because the chest x-rays from the same patient are highly correlated.
- Text Task: classify medical notes based on what diseases are described. Here, again, the data must be split based on patient identifier, because medical notes written about the same patient are highly correlated. A patient who has diabetes and cystic fibrosis today is going to have diabetes and cystic fibrosis tomorrow, too.
- Tabular Data Task: predict the risk of hospital admission based on tabular data collected from the electronic medical record, including diagnoses, procedures, medications, demographics, and laboratory values. Let’s say you’re considering data from a large hospital over a five-year period. It is essentially guaranteed that at least one patient will be admitted more than once to the hospital during that period. If Mr. Smith has been admitted to the hospital 3 times, then each of those 3 admission examples should be assigned to the same set.
Typically, the patient identifier is the medical record number, or MRN. This is a form of protected health information, so if you are using a de-identified data set, there will be a randomly-generated patient identifier to replace the original MRN.
Summary
- To train and evaluate a machine learning model, split your data into three sets, for training, validation, and testing.
- If you are developing a new machine learning model, you should finalize the model and the hyperparameters using the validation set. Then you should use the test set only once, to assess the generalization ability of your chosen model.
- If you are working with a medical data set, the splits should be based on patient identifier, and not on the individual examples.

Credit: xkcd “machine learning”
About the Featured Image
The featured image is modified from a Wikipedia picture of Oregon’s Three Sisters – three adjacent volcanoes known as the South Sister, Middle Sister, and North Sister.
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

#/media/File:Three_sisters2.jpg){kind=link}
Comments are closed.