

This post will discuss the Universal Transformer, which combines the original Transformer model with a technique called Adaptive Computation Time. The main innovation of Universal Transformers is to apply the Transformer components a different number of times for each symbol.
Paper Reference
Dehghani M, Gouws S, Vinyals O, Uszkoreit J, Kaiser Ł. Universal transformers. ICLR 2019.
Background and Transformer Review
If you are not already familiar with the Transformer model, you should read through “The Transformer: Attention is All You Need.” The Universal Transformer is a simple modification of the Transformer, so it is important to understand the Transformer model first.
If you’re already familiar with the Transformer model and would like a quick review, here goes:
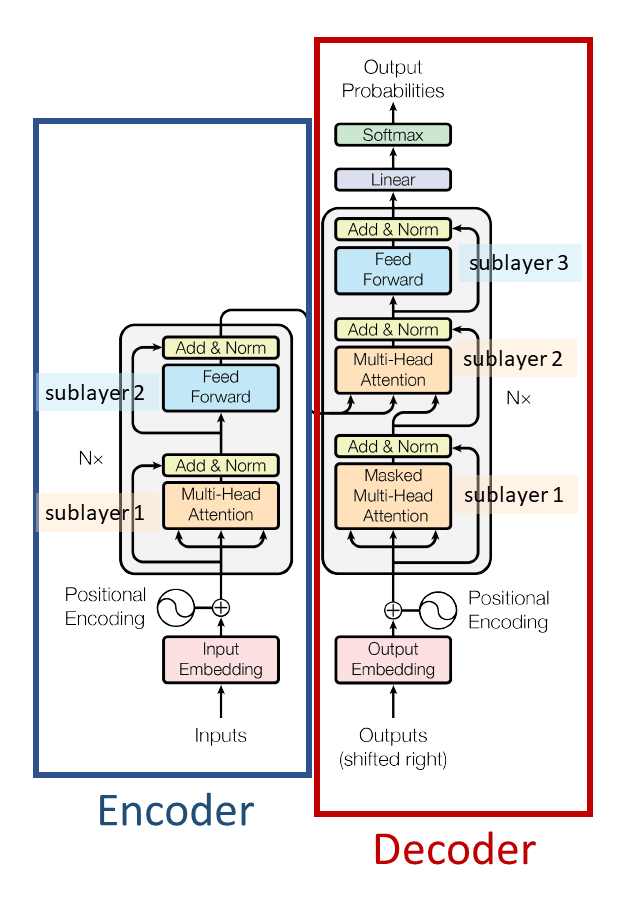
Figure modified from Transformer paper
The base Transformer consists of an encoder and a decoder:
- Encoder:
- 6 encoder layers
- Each encoder has 2 sub-layers: (1) multi-head self-attention; (2) feed-forward
- Decoder:
- 6 decoder layers
- Each decoder layer has 3 sub-layers: (1) masked multi-head self-attention; (2) encoder-decoder multi-head attention; (3) feed forward
Here’s a one-figure review of multi-head attention, one of the Transformer model’s key innovations:

Multi-head attention is used for encoder self-attention (which takes as input the previous encoder layer output), decoder self-attention (which takes as input the previous decoder layer output), and encoder-decoder attention (which uses the final encoder output for the keys and values and the previous decoder output as the queries.) In the figure above the parts of the model where multi-head attention is used are boxed in red on the left. On the right, the dimensions of the Tensors at each part of the multi-head attention calculation are shown.
Finally, here’s a quick review of the position-wise fully connected feed forward network that’s used in the encoder sub-layers and in the decoder sub-layers:

Motivation for the Universal Transformer
The original Transformer is a natural language processing model that processes all words in the input sequence in parallel, while making use of attention mechanisms to incorporate context. It’s faster to train than an RNN, which has to process input tokens one-by-one. It achieves good performance on language translation. However, it has poorer performance on algorithmic tasks like string copying (e.g. given ‘abc’ as input, output ‘abcabcabc.’)
The Neural GPU and Neural Turing Machine (different kinds of models) have poorer performance on language translation but good performance on algorithmic tasks.
The goal of the Universal Transformer is to achieve good performance on both language translation and algorithmic tasks with only one model. The authors of the Universal Transformer also note that it is a Turing-complete model. (“Turing-complete” means it can simulate any Turing machine, which is a formal definition of a computer.)
Overview
In the Universal Transformers paper, the authors provide a new figure to describe their model:
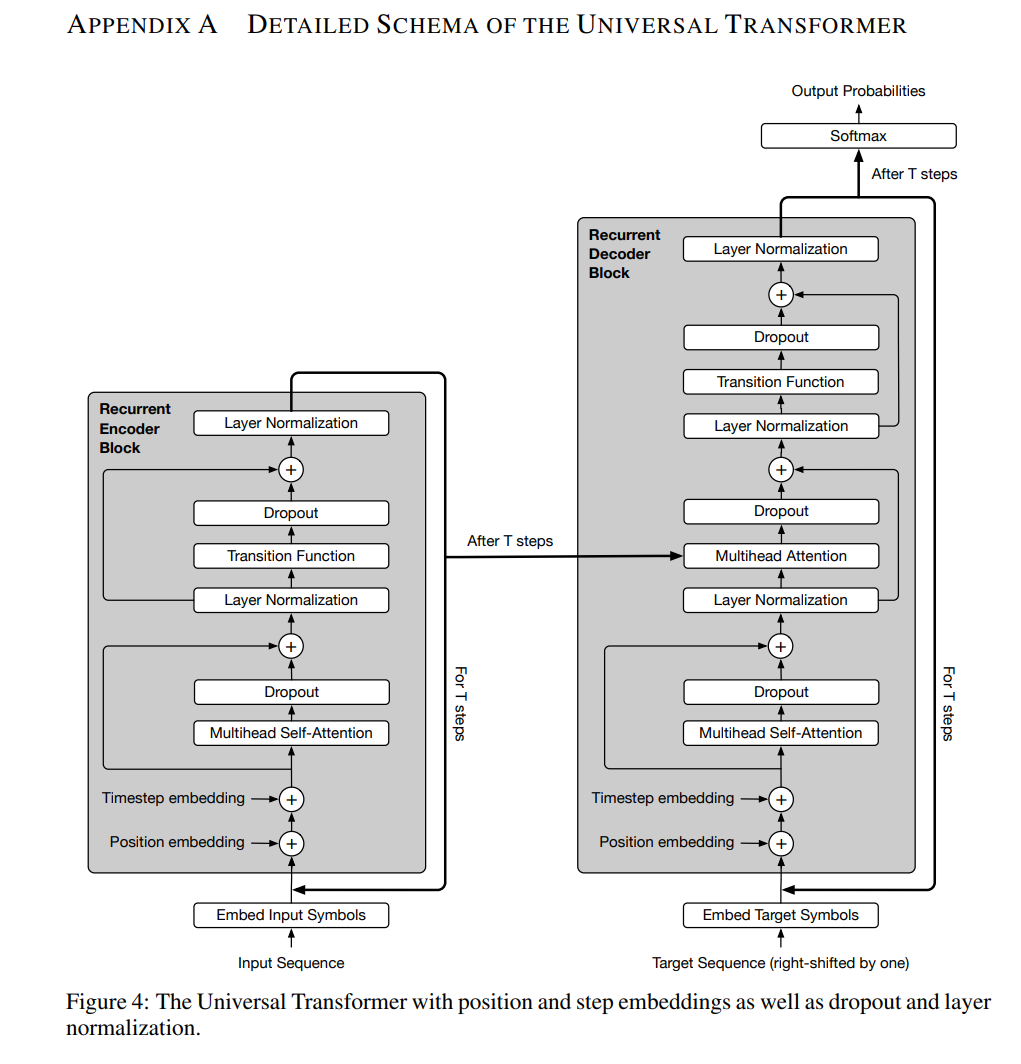
Figure 4 from Universal Transformer paper
However, I think that the use of a different figure style relative to the original Transformer paper obscures the key differences between the models. Thus, I have modified the figure from the original Transformers paper to more clearly emphasize the similarities and differences of the Transformer and Universal Transformer models. Key differences are emphasized in red:
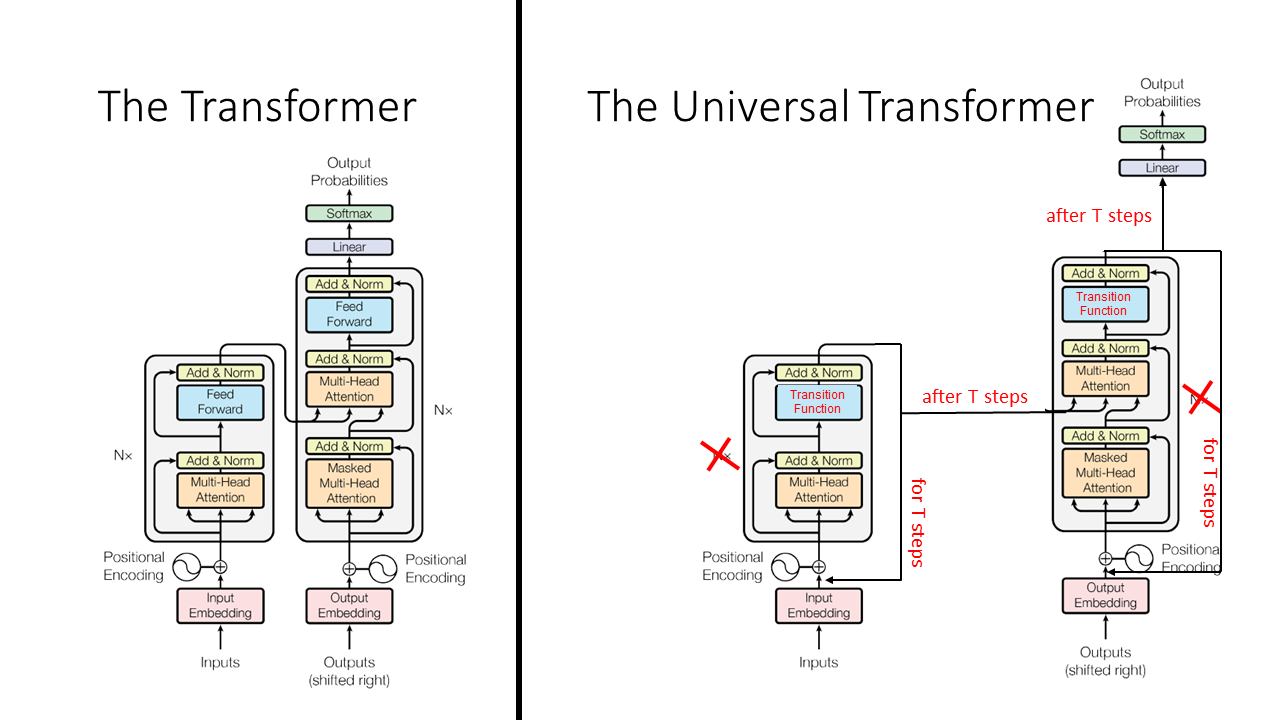
They key differences between the Transformer and the Universal Transformer are as follows:
- The Universal Transformer applies the encoder for a variable number of steps for each input token (T steps), while the base Transformer applies exactly 6 encoder layers.
- The Universal Transformer applies the decoder for a variable number of steps for each output token (T steps), while the base Transformer applies exactly 6 decoder layers.
- The Universal Transformer uses a slightly different input representation: it includes a “timestep embedding” in addition to the “positional encoding.”
Differences (1) and (2), the variable numbers of steps, are achieved through use of “Adaptive Computation Time” which will be described more later. In brief, Adaptive Computation Time is a dynamic per-position halting mechanism that allows for different amounts of computation on each symbol.
The Universal Transformer is a “parallel-in-time self-attentive recurrent sequence model” which is parallelizable over the input sequence. Like the base Transformer, it has a “global receptive field” (meaning it looks at a lot of words at once.) The main new idea is that in each recurrent step, the Universal Transformer iteratively refines its representations for all symbols in the sequence using self-attention followed by a “transition function” shared across all positions and time-steps.
Here is a cool animation from Oriol Vinyals (@OriolVinyalsML on Twitter) that illustrates the Universal Transformer:
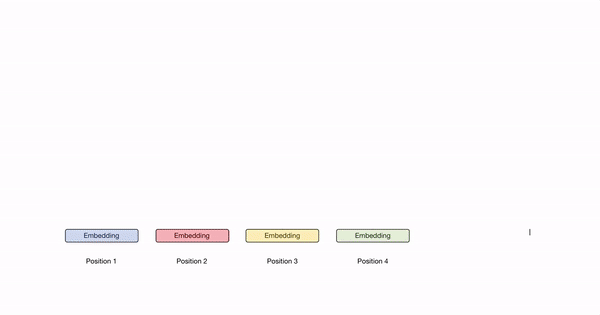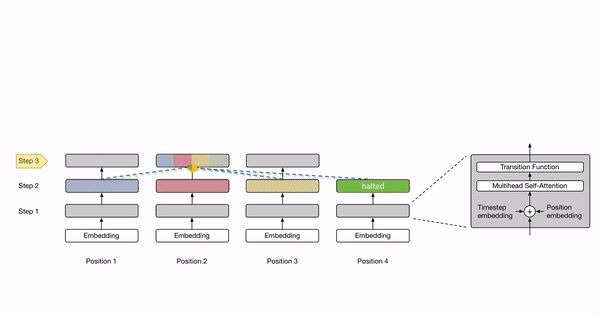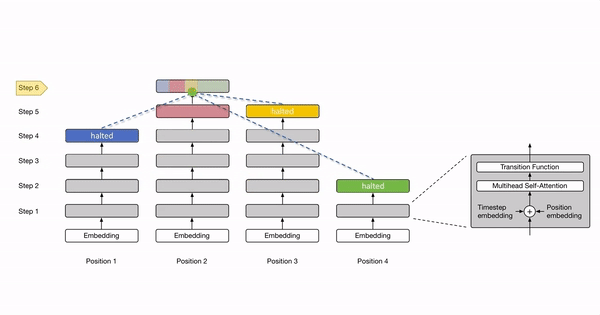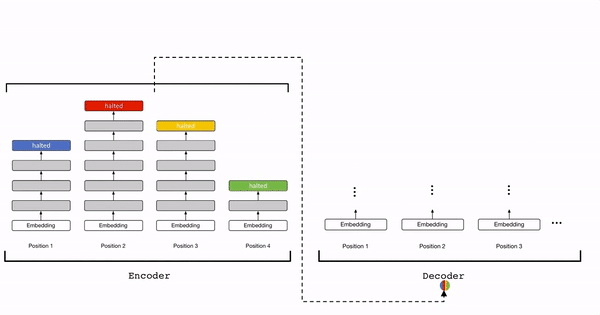
The parameters of the Universal Transformer, including the self-attention and the transition weights, are tied across all positions and time-steps. If the Universal Transformer is run for a fixed number of steps (rather than a variable number of steps T), then the Universal Transformer is equivalent to a multi-layer Transformer with tied parameters across all layers.
Here’s another cool animation of the Universal Transformer, this one from the Google AI Blog:
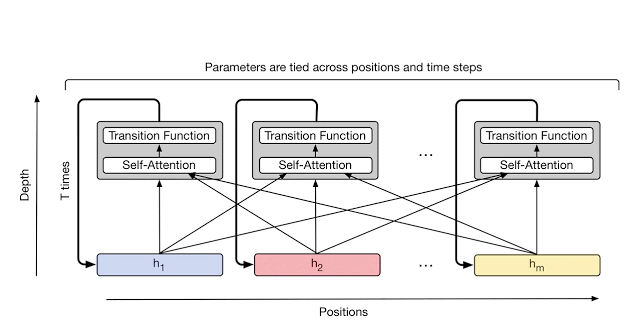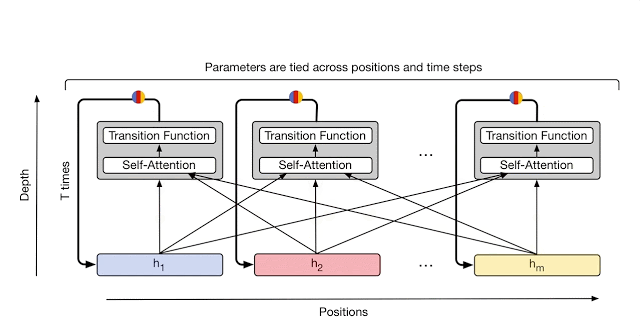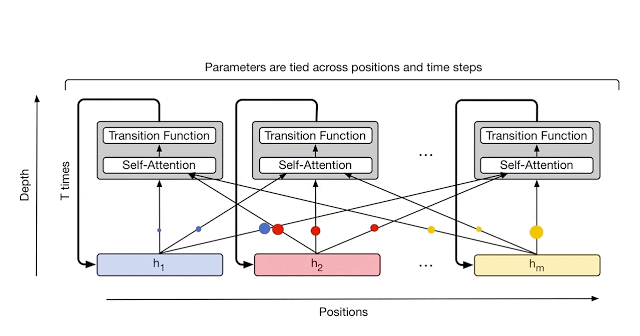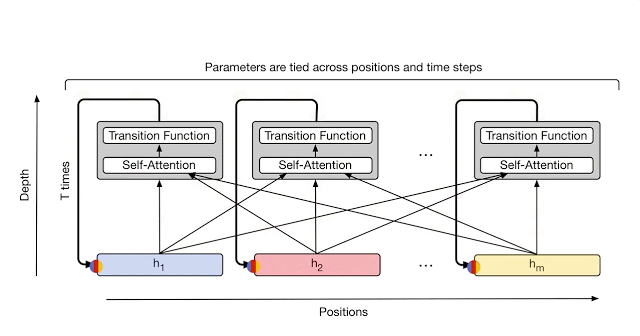
More Details on the Universal Transformer
Universal Transformer Input
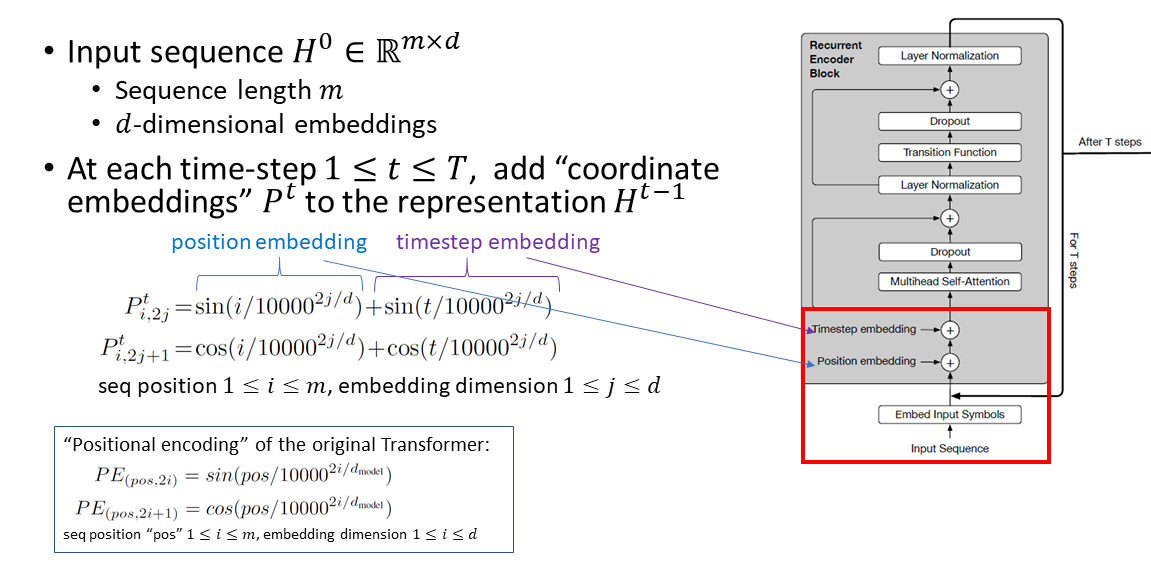
As shown in the figure above, the input to the Universal Transformer is a sequence of length m, represented as d-dimensional embeddings. At every time step, “coordinate embeddings” are added. These “coordinate embeddings” consist of a position embedding (the same as a position embedding of the original Transformer) and a timestep embedding (similar concept as the position embedding except it is based on the time t instead of the position i.)
Universal Transformer Encoder
The first part of the Universal Transformer encoder is multi-headed self-attention, which is exactly the same as the first part of the original Transformer encoder.
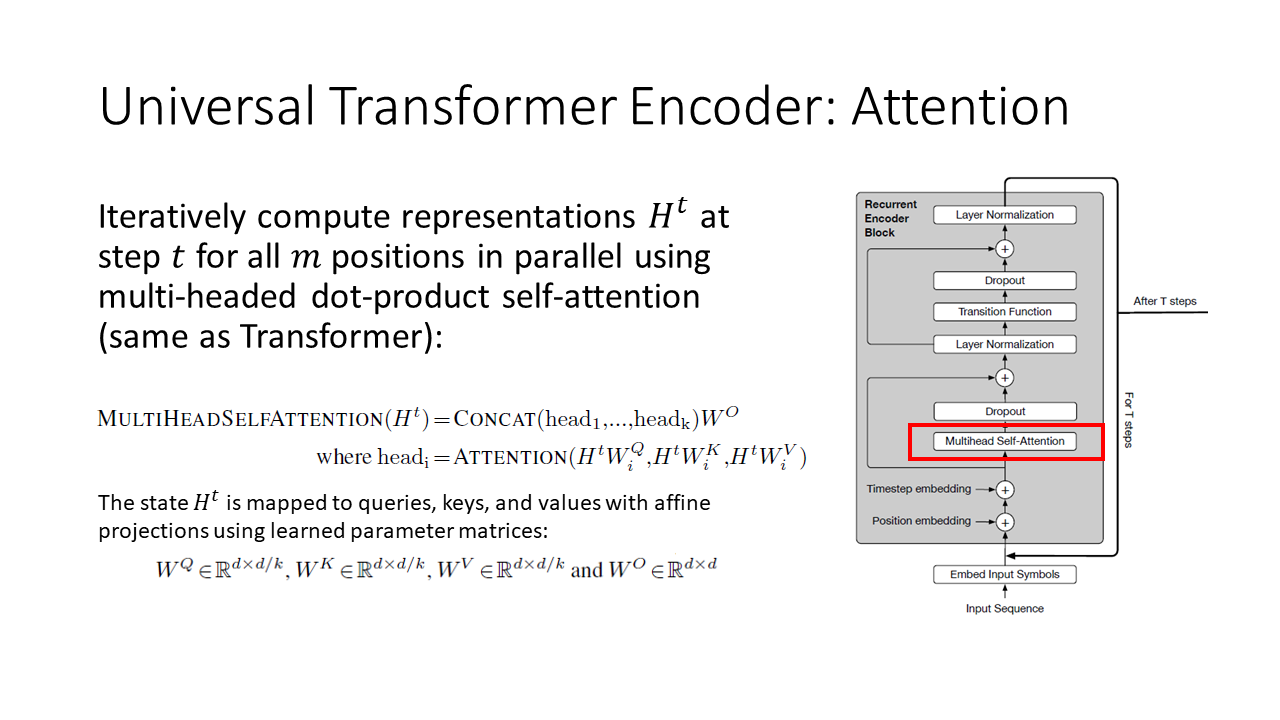
The second part of the Universal Transformer encoder is a transition function. The transition function can be a position-wide fully-connected neural network, in which case this is exactly the same as the second part of the original Transformer encoder. Alternatively, the transition function can be a separable convolution. The authors don’t discuss when they use the position-wise fully-connected networks versus separable convolutions, but presumably this choice influences the performance of the Universal Transformer on different tasks.
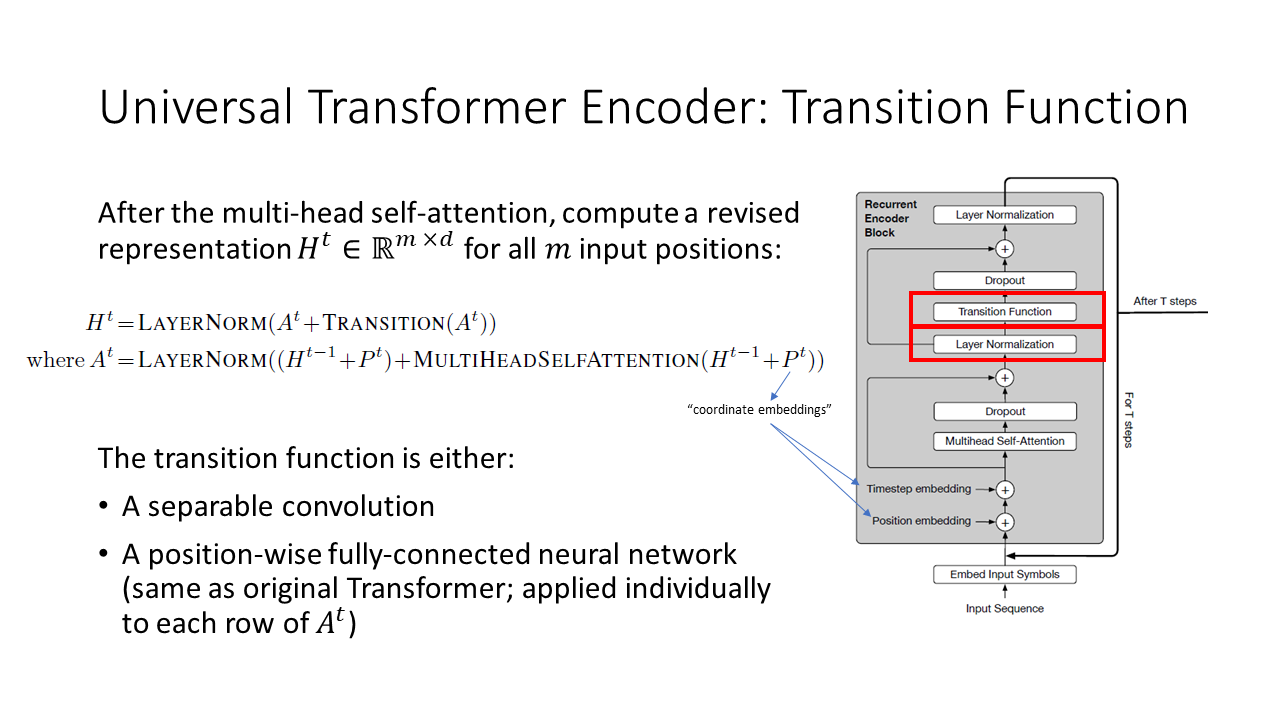
What is separable convolution? A separable convolution splits a convolutional kernel into two separate kernels that do two convolutions:
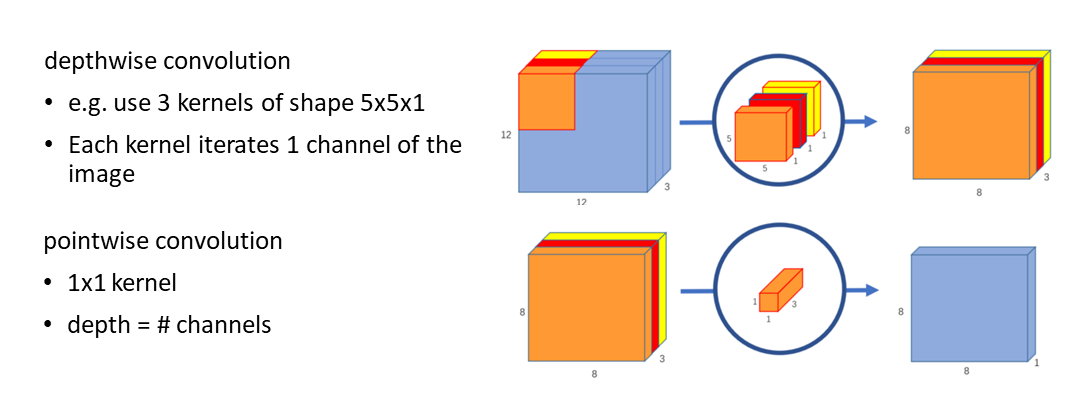
Figure modified from “Separable Convolutions” by Chi-Feng Wang
If you’re interested in more details on separable convolution, you can see this paper: Francois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv 2016
And that’s it for the Universal Transformer encoder! The Universal Transformer encoder is identical to the original Transformer encoder if you choose a position-wise feed-forward network as the transition function.
Universal Transformer Decoder
Similarly, the Universal Transformer decoder is identical to the original Transformer decoder if you choose a position-wise feed-forward network as the transition function. There are three decoder sub-layers:
- Sub-layer 1: multi-headed self-attention (on previous decoder output)
- Sub-layer 2: multi-headed encoder-decoder attention. Queries are obtained by projecting previous decoder outputs. Keys and values are obtained by projecting final encoder output.
- Sub-layer 3: transition function.
Universal Transformer Decoder Training
One nice aspect of the Universal Transformer paper is that it provides more background on how the decoder is trained. This is also applicable to the original Transformer but wasn’t discussed in this much detail in the original Transformer paper.
The Transformer decoder (original and Universal) is “auto-regressive” meaning it generates one output symbol at a time, and the decoder consumes its previously-produced outputs.
It is trained using “teacher-forcing” which means during training, ground truth embedded target symbols are fed in (rather than the decoder’s own possibly incorrect predictions.) The target symbols are shifted right (so the model can’t see the current word it’s supposed to predict) and masked (so the model can’t see future words.)
In the Universal Transformer, per-symbol target distributions are obtained as follows:

Adaptive Computation Time (ACT)
This is the main contribution of the Universal Transformers paper: they apply Adaptive Computation Time, which was originally developed in RNNs, to the Transformer model:
This is the mechanism that allows application of the encoder a variable number of times and application of the decoder a variable number of times.
ACT dynamically modulates the number of computational steps needed to process each input symbol (“ponder time”) based on a scalar “halting probability” that is predicted by the model at every step. Universal Transformers apply a dynamic ACT halting mechanism to each position (e.g. each word) separately. Once a particular recurrent block halts, its state is copied to the next step until all blocks halt, or until a maximum number of steps is reached. The final output of the encoder is the final layer of representations produced in this fashion.
Here is a quick summary of how ACT works:
- At each step we are given:
- Halting probabilities and the previous state (initialized as zeros)
- A scalar halt threshold between 0 and 1 (a hyperparameter – i.e. we choose the halt threshold ourselves)
- First we compute the new state for each position, using the Universal Transformer
- Then we compute the “pondering” value using a fully-connected layer that takes the state down to dimension 1, and applies a sigmoid activation to make the output a probability-like value between 0 and 1. This is the pondering value. The “pondering” value is the model’s estimation of how much additional computation is needed for each of the input symbols
- We decide to halt for any positions that cross the halt threshold:
- Just halted at this step: (halting probability + pondering) > halt threshold
- Still running: (halting probability + pondering) ≤ halt threshold
- For positions that are still running, update the halting probability: halting probability += pondering
- Update the state of the other positions until the model halts for all positions or reaches a predefined max number of steps
For an implementation of Adaptive Computation Time, see this Github repository.
Turing Completeness
The authors of the Universal Transformer paper explain that the Universal Transformer is Turing-complete, just as the Neural GPU is Turing-complete. If you are not familiar with Turing completeness or proofs that “reduce” models to each other, you can skip this section.
In brief, the authors show that Universal Transformers are Turing-complete by reducing a Neural GPU to a Universal Transformer:
- Ignore the decoder
- Make the self-attention module the identity function
- Assume the transition function is a convolution
- Set the total number of recurrent steps T to equal the input length
- We have obtained a Neural GPU from a UT
Results
We’ve now gone through all the key concepts in Universal Transformers. What are Universal Transformers good at?
There are five tasks in the Universal Transformers paper, summarized here:

On bAbi Question Answering, the Universal Transformer obtains better performance than the original Transformer. Furthermore, the average ponder time (how many times the Universal Transformer computes on a symbol) over all positions in all samples in the test data was higher for more difficult variants of the task (variants where more supporting facts are required to answer the question.) This implies that the Universal Transformer “thinks more” when the task is harder.
In the Universal Transformers paper, there are several visualizations of attention weights over different time steps of the bAbi task. The visualizations are based on different heads over all facts in a bAbi story and a question. The four different attention heads correspond to four different colors:

Figure 5 from the Universal Transformers paper.
For more such figures, you can see the paper appendix.
The Universal Transformer also achieves good performance on Subject-Verb Agreement and LAMBADA. On LAMBADA, the authors noticed that the Universal Transformer was taking an average of 8 – 9 steps; however the base Transformer they were comparing to had only 6 layers. So, they ran a base Transformer with 8 – 9 layers, but found that the Universal Transformer still outperformed this deeper Transformer variant. This suggests that more computation isn’t always better, and there is some value in computing less on certain symbols in the input and output sequences. The authors speculate that the Adaptive Computation Time may have a regularization effect, e.g. by helping the model ignore (“compute less on”) information that isn’t important for solving the task.
Finally, the authors show that the Universal Transformer achieves good performance on several algorithmic tasks including copy, reverse, and addition. The Universal Transformer also outperforms the base Transformer on English-German machine translation.
Summary
- Universal Transformer = original Transformer + Adaptive Computation Time
- The Universal Transformer allows simultaneous evolution of per-symbol hidden states, which are generated by attending to the sequence of hidden states at the previous step.
- The Universal Transformer achieves improved performance on a variety of tasks.
Presentation
For a version of this Universal Transformers blog post formatted as a PowerPoint presentation, please follow this link.
Featured Image
The featured image is a crop from the painting “The Crystal Ball” by John William Waterhouse, combined with an image of “the universe” (various galaxies) from Wikipedia and a cartoon sun.
As an independent researcher (MD + AI PhD + 7 yrs prior founder/CEO experience), I build and evaluate cutting-edge healthcare AI for startups. Contact me to learn more.
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

{kind=link}
{kind=link}
{kind=link}