

This post summarizes three closely related methods for creating saliency maps: Gradients (2013), DeconvNets (2014), and Guided Backpropagation (2014). Saliency maps are heat maps that are intended to provide insight into what aspects of an input image a convolutional neural network is using to make a prediction. All three of the methods discussed in this post are a form of post-hoc attention, which is different from trainable attention. Although in the original papers these methods are described in different ways, it turns out that they are all identical except for the way that they handle backpropagation through the ReLU nonlinearity.
Please stay tuned for the next post, “CNN Heat Maps: Sanity Checks for Saliency Maps” for a discussion of a 2018 paper by Adebayo et al. which suggests that out of these three popular methods, only “Gradients” is effective. Specifically, “Gradients” passes Adebayo et al.’s sanity checks, DeconvNets were not tested, and Guided Backpropagation fails the sanity checks.
In spite of the discouraging sanity check results for Guided Backpropagation (which by extension is also discouraging for DeconvNets, as we shall see that the methodology for DeconvNets is overlaps that of Guided Backpropagation), I am still writing about DeconvNets and Guided Backpropagation in this post for several reasons:
- Historical popularity. Both the DeconvNet and the Guided Backpropagation paper have been cited over 1,000 times.
- Considering the Gradients, DeconvNet, and Guided Backpropagation approaches together in the same post is an interesting case study of how similar ideas can be presented in different ways, relatively simultaneously in the research community.
- Thinking about these methods requires understanding how backpropagation through ReLU nonlinearities works.
Papers
- Gradients: Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013 Cited by 1,720
- DeconvNets: Zeiler MD, Fergus R. Visualizing and understanding convolutional networks. ECCV 2014 Cited by 7,131
- Guided Backpropagation: Springenberg JT, Dosovitskiy A, Brox T, Riedmiller M. Striving for simplicity: The all convolutional net. arXiv 2014 Cited by 1,504
A note on terminology: the method which is referred to as “Gradients” in this post (following Adebayo et al.) is sometimes also referred to as “backpropagation” or even just “saliency mapping” – although the other two techniques (DeconvNets and Guided Backpropagation) are also ways to accomplish “saliency mapping.”
Overview
All these methods produce visualizations intended to show which inputs a neural network is using to make a particular prediction. They have been used for weakly supervised object localization (because the approximate position of the object is highlighted) and for gaining insight into a network’s misclassifications.
In the iPython notebook, “Saliency Maps and Guided Backpropagation,” Jan Schluter explains the relationship between these three related methods:
The common idea is to compute the gradient of the network’s prediction with respect to the input, holding the weights fixed. This determines which input elements (e.g., which pixels in case of an input image) need to be changed the least to affect the prediction the most. The sole difference between the three approaches is how they backpropagate through the linear rectifier [(the ReLU)]. Only [Simonyan et. al’s “Gradients” approach] actually computes the gradient; the others modify the backpropagation step to do something slightly different. As we will see, this makes a crucial difference for the saliency maps!
(Note: This iPython notebook was created in 2015, well before the Adebayo et al. sanity checks suggested that Guided Backpropagation is ineffective.)
Gradients (Vanilla Backpropagation)
For a detailed discussion of this method see the post “CNN Heat Maps: Saliency/Backpropagation.” The “Gradients” approach makes use of vanilla backpropagation through the ConvNet.
DeconvNets
DeconvNets are the same as the “Gradients” approach except for a difference in backpropagation through the ReLU nonlinearity.
The DeconvNet approach was not specifically tested by Adebayo et al.’s sanity checks.
Note that “deconvolution” can be a confusing term. In this context, “deconvolution” refers to performing convolution with the same filters transposed. This kind of deconvolution is also referred to as “transposed convolution.” Transposed convolution is a critical part of the backward pass in any ConvNet – i.e., transposed convolution is also used in vanilla backpropagation.
To quote Jan Schluter again (with some bracketed insertions),
The central idea of Zeiler et al. [in the DeconvNet paper] is to visualize layer activations of a ConvNet by running them through a “DeconvNet” — a network that undoes the convolutions and pooling operations of the ConvNet until it reaches the input space. Deconvolution is defined as convolving an image with the same filters transposed, and unpooling is defined as copying inputs to the spots in the (larger) output that were maximal in the ConvNet (i.e., an unpooling layer uses the switches from its corresponding pooling layer for the reconstruction). Any linear rectifier [(ReLU)] in the ConvNet is simply copied over to the DeconvNet [which the key difference from vanilla backpropagation]. […]
This definition of a DeconvNet exactly corresponds to simply backpropagating through the ConvNet [i.e., the standard Gradients approach], except for the linear rectifier[: in a DeconvNet, we only] propagate back all positive error signals:
. Note that this is equivalent to applying the linear rectifier to the error signal.
In detail, here are the steps for building a DeconvNet visualization from a trained ConvNet. These steps are based on a helpful Quora post by Samarth Brahmbhatt:
- Choose a filter activation to visualize. e.g. the 10th filter of the 2nd conv layer. You want to find the patterns in image space that cause this filter activation to be high. You should choose a filter that has high-magnitude activations.
- Do a forward pass of the image through the ConvNet up to and including the layer where your chosen activation is.
- Zero out all the channels (filters) in the chosen layer except for the filter activation you want to visualize.
- Travel back to the image space through a DeconvNet which has the same structure as the ConvNet, except with inverse operations:
- Unpooling: in the ConvNet you must remember the position of the maximum lower layer activation by storing this position in a “switch variable”. Then in the DeconvNet, you copy/paste the activation from the upper layer into the position indicated by the switch variable, and all the rest of the lower-layer activations are set to zero. The positions saved in the switch variables will change based on the input image. (This is the same as what you do in vanilla backpropagation.)
- ReLU: apply the linear rectifier (the ReLU) to the error signal. (This is NOT how ReLUs are handled in vanilla backpropagation. Thus, this step is the key difference between the “Gradients” approach to saliency mapping, which uses vanilla backpropagation, and the DeconvNet approach to saliency mapping.)
- Deconvolution: use the same filters as the corresponding convolutional layer except that they are flipped horizontally and vertically. (This is the same as what you do in vanilla backpropagation. For a detailed discussion of flipping convolutional filters, see the post “Convolution vs. Cross-Correlation.”)
- In the image layer you will see a pattern which is the pattern the selected activation is sensitive to.
Additional References on DeconvNets and Deconvolution:
- Tensorflow discussion about deconvolution op
- Tensorflow deconv2d function implementation
- Deconvolution and checkerboard artifacts (Distill)
- DeconvNet Unpooling Layer (Semantic Segmentation)
- What are deconvolutional layers?
Guided Backpropagation
Guided backpropagation, also known as guided saliency, is the last of our three related techniques. Guided backpropagation produces visualizations that look like this (figure from utkuozbulak/pytorch-cnn-visualizations):


You can see that the snake, mastiff (dog), and spider are each “highlighted” in fine lines.
Guided Backpropagation basically combines vanilla backpropagation and DeconvNets when handling the ReLU nonlinearity:
- Like DeconvNets, in Guided Backpropagation we only backpropagate positive error signals – i.e. we set the negative gradients to zero (ref). This is the application of the ReLU to the error signal itself during the backward pass.
- Like vanilla backpropagation, we also restrict ourselves to only positive inputs.
Thus, the gradient is “guided” by both the input and the error signal.
If the differences between the three methods aren’t clear yet, never fear! The next sections will provide another angle of insight into Gradients, DeconvNets, and Guided Backpropagation, this using additional figures and equations.
Gradients (Vanilla Backpropagation) ReLU Figure & Equations
As we have now emphasized several times, all three methods handle backpropagation through the ReLU differently.
Figure 1 in Springenberg et al. compares the three approaches:

Let’s dissect and rearrange this figure to study it in detail.
First, here is a summary of vanilla backpropagation through a ReLU (“Gradients”). In this figure, f represents a feature map produced by some layer of a CNN, and R represents an intermediate result in the calculation of backpropagation. (When we reach the very beginning of the network again, after finishing backpropagation, R is our reconstructed image.)

At the top of this figure, we see an example of a ReLU operation in the forward pass. As a recap, here are the equations for a ReLU (for the forward pass) and a ReLU derivative (for the backward pass) (equations from here):

In the middle of the figure, we see the calculation of (f_i^l > 0) for use in the backward pass. This is just figuring out which elements of the preceding feature map are greater than zero. We get a binary map for (f_i^l > 0) where anything less than or equal to zero is zero, and anything positive is 1 — since the derivative of ReLU is equal to 1 everywhere that x is positive.
Finally, in the last part of the figure, we see how we use (f_i^l > 0) in the backward pass. We merely multiply (f_i^l > 0) against R_i^{l+1} (our intermediate backpropagation result so far) to obtain R_i^l.
This is how vanilla backpropagation works through a ReLU unit, and this is what is used in the “Gradients” saliency map technique.
DeconvNet ReLU Figure & Equations
Now we’ll take a look at how the DeconvNet handles backpropagation through a ReLU. The DeconvNet only backpropagates positive error signals (i.e. it sets all the negative error signals to zero):
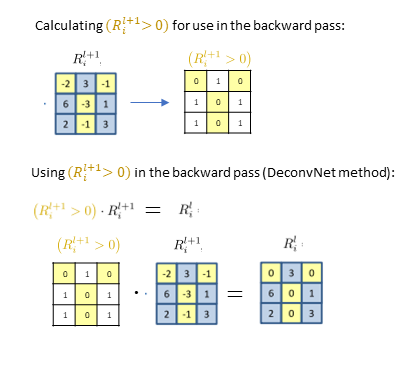
We first calculate everywhere that R_i^{l+1} is greater than 0 – i.e., everywhere that we have a positive error signal. Then we multiply this binary mask against R_i^{l+1}, the error signal itself. Note that this is the same as calculating ReLU( R_i^{l+1} ).
We can see from the above figures and equations that this DeconvNet approach is different from the vanilla backpropagation approach.
Guided Backpropagation ReLU Figure & Equations
Finally, we’ll look at how Guided Backpropagation deals with ReLUs. Essentially, Guided Backpropagation incorporates both the vanilla backpropagation approach and the DeconvNet approach:
- In Guided Backpropagation, we only backpropagate positive error signals (like the DeconvNet yellow equations)
- In Guided Backpropagation, we also restrict to only positive inputs, i.e. positive parts of f_i^l (like the vanilla backpropagation red equations):
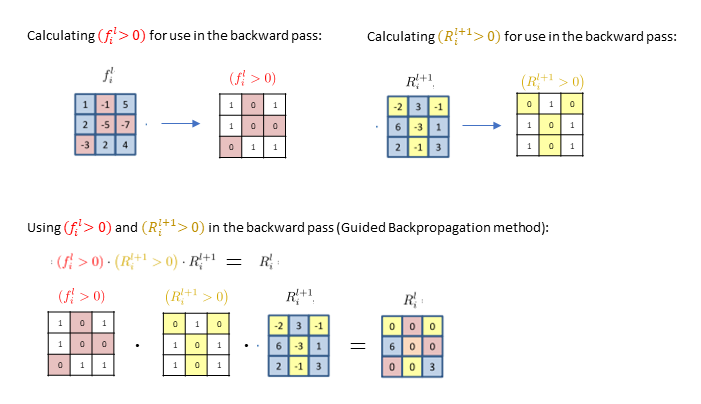
Thus, Guided Backpropagation, we end up with more zeros in our final output than in either of the other methods.
Summary
We have now finished comparing three popular techniques for creating CNN saliency maps: Gradients (vanilla backpropagation), DeconvNets, and Guided Backpropagation.
- “Gradients” uses vanilla backpropagation, including at the ReLUs. In vanilla backpropagation, ReLUs are handled by making use of which elements are positive in the preceding feature map.
- “DeconvNets” uses vanilla backpropagation, except at the ReLUs. In DeconvNets, at ReLUs only positive error signals are backpropagated, which corresponds to applying a ReLU operation to the error signal itself.
- “Guided Backpropagation” uses vanilla backpropagation, except at the ReLUs. Guided Backpropagation combines vanilla backpropagation at ReLUs (leveraging which elements are positive in the preceding feature map) with DeconvNets (keeping only positive error signals.)
Of these three options, Adebayo et al. recommend choosing “Gradients” as we will see in a future post.
Featured Image
The featured image is a brightened version of a crop from Figure 3 of Springenberg et al.’s paper showing guided backpropagation visualizations.
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

Comments are closed.