

How do self-driving cars read street signs? How does Facebook automatically tag you in pictures? How does a computer achieve “dermatologist-level” classification of skin diseases?
In all these applications, a computer must “see” the world: it takes in a numerical representation of electromagnetic radiation (e.g. a photograph), and it figures out what that radiation means.
Computer vision is a broad field that combines artificial intelligence, engineering, signal processing, and other techniques, to allow computers to “see.” A convolutional neural network (“CNN”) is one kind of computer vision model.
CNNs have enjoyed a surge in popularity over the past several years due to their excellent performance on many useful tasks. CNNs are used for all of the computer vision applications described in the first paragraph, from labeling aspects of a photograph to medical image interpretation. This post will provide an overview of how CNNs enable many exciting modern computer vision applications.
Background
CNN Inputs: How Pictures are Represented in a Computer
The input to a CNN for a computer vision application is an image or a video. (CNNs can also be used on text, but we will save that for another post.)
In computers an image is represented as a grid of pixel values — i.e. a grid of positive whole numbers. Here’s a simple example where the pixel color “white” is represented by 0, yellow is represented by 2, and black is represented by 9. (For ease of visualization the colors are still displayed on the “picture representation” side, even though in the computer only the numbers are saved):

In practice, color images are represented using three grids of numbers stacked on top of each other: one grid for red, one grid for green, and one grid for blue. The elements of each grid specify the strength of the red, green, or blue color for each pixel, using a number between 0 and 255. For more details about how color images are represented, see the RGB color model.
For the remainder of this post we will use the simplified smiley face example shown above.
CNN Outputs
The output of a CNN depends on the task. Here are some example CNN inputs and outputs for a variety of classification tasks:
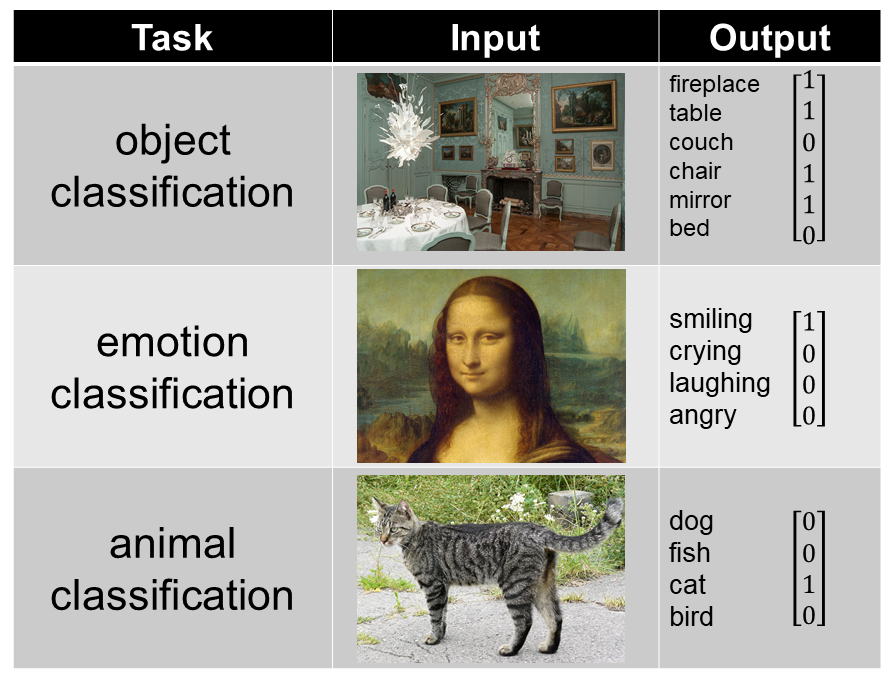
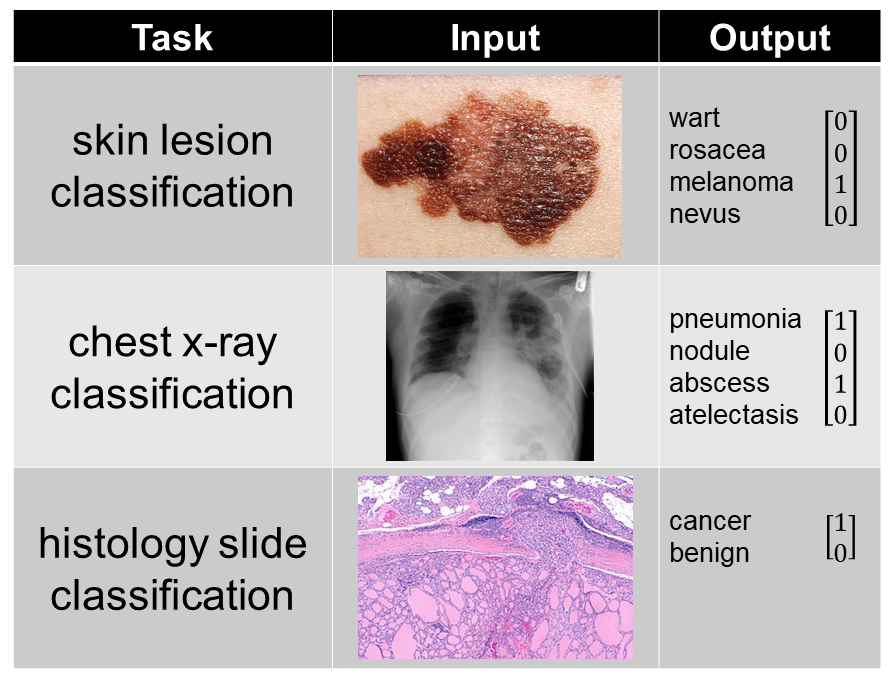
image sources: blue dining room, Mona Lisa, cat, melanoma, chest x-ray, follicular thyroid carcinoma
When training a CNN for any task, many training examples are required. For instance, if you were to train a CNN on animal classification, you would need a data set of thousands of animal pictures, where each picture is paired with a binary vector indicating which animals are present in that images. For more information on training and testing neural networks, see this post.
The General Idea
In a CNN, different “filters” (little grids of numbers) slide across an entire image, computing the convolution operation. Different filters with different numbers in them will detect different aspects of the image, like horizontal vs. vertical edges. Many different filters are used in a CNN, to identify many different aspects of an image.
This animation shows a 2 x 2 filter sliding across the top part of the smiley face image:

Parts of a CNN
Like a feedforward neural network, a CNN is made up of “layers.”
A single layer in a CNN includes three kinds of calculations:
- Convolution: This is the heart of the CNN. The convolution operation uses only addition and multiplication. Convolutional filters scan the image, performing the convolution operation.
- Nonlinearity: This is an equation applied to the output of the convolutional filter. Nonlinearities allow the CNN to learn more complicated relationships (curves instead of lines) between the input image and the output class.
- Pooling: This is often “max pooling” which is just choosing the biggest number out of a small bag of numbers. Pooling reduces the size of the representation, thereby reducing the amount of computation required and making the CNN more efficient.
These three kinds of calculations – convolution, a nonlinearity, and pooling – are used to build the “convolutional” part of a CNN model. A CNN that uses only these operations to obtain the final predictions is referred to as a “fully convolutional network.” This is in contrast to a CNN that uses some fully-connected layers after the convolutional part (fully connected layers are the building blocks of feedforward neural networks.)
What Is “Learned”
A CNN is a kind of machine learning algorithm. What exactly is the CNN learning?
It’s learning what values to use inside the convolutional filters, in order to predict the desired outputs. Filters containing different values detect different characteristics of the image. We don’t want to tell the model what characteristics it needs to look for to determine if there’s a cat in the picture; the model learns on its own what values to choose in each of the filters in order to find cats.
If there are fully connected layers at the end, a CNN will also learn what numbers to use in the fully connected layers.
A Convolutional Filter
A CNN filter is a square grid of numbers. The filter sizes are specified when you build the CNN. Some commonly used filter sizes are 2 x 2, 3 x 3, and 5 x 5, but they can be any size that you choose.
When a CNN is initialized before any training has occurred, all the values for the filters are set to random numbers. Through the process of training, the CNN tunes the values in the filters so that the filters detect meaningful characteristics of the images. Here are some examples of convolutional filters of different sizes that have been randomly initialized:
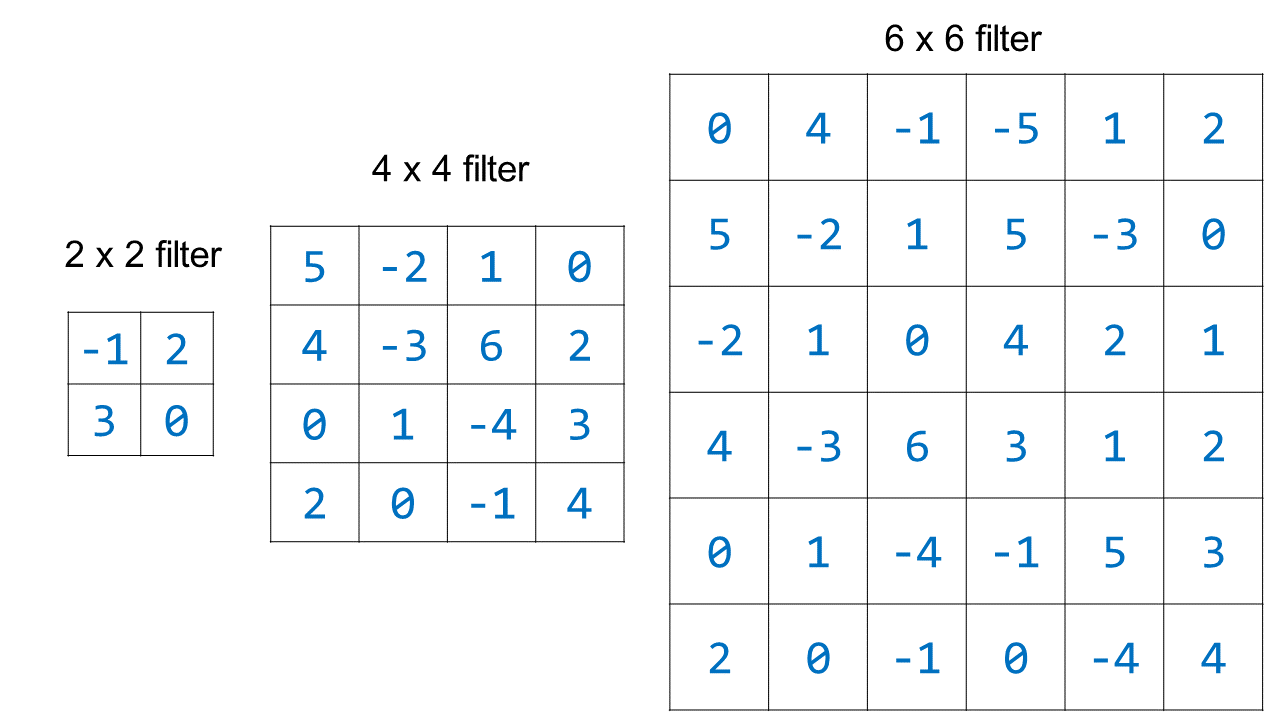
Note that in practice the numbers chosen for the random initialization would be smaller, and they wouldn’t all be integers (e.g. randomly initialized filter values might be -0.045, 0.234, -1.10, etc.)
The Convolution Operation
Here’s how convolution works. Let’s take a tiny piece of the smiley face image, and apply convolution to it, using a 2 x 2 filter with the values (1, 2, 3, and -1):
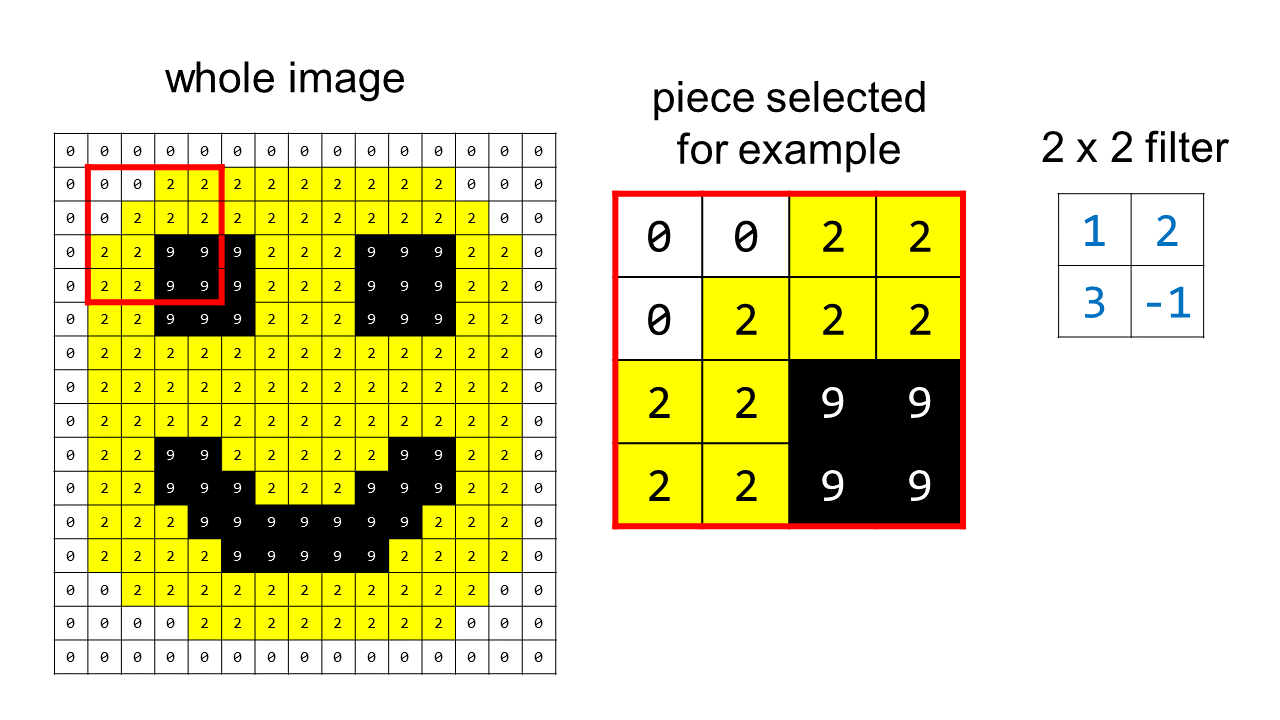
Setup for the example:
- The filter we are using is shown on the left for reference, with its values in blue font.
- The 2 x 2 section of the image that is being convolved with the filter has its values highlighted in red.
- The calculation in the middle shows the convolution operation, where we match up the elements of the filter with the elements of the picture, multiply the corresponding numbers together, and then sum them to get the convolution output.
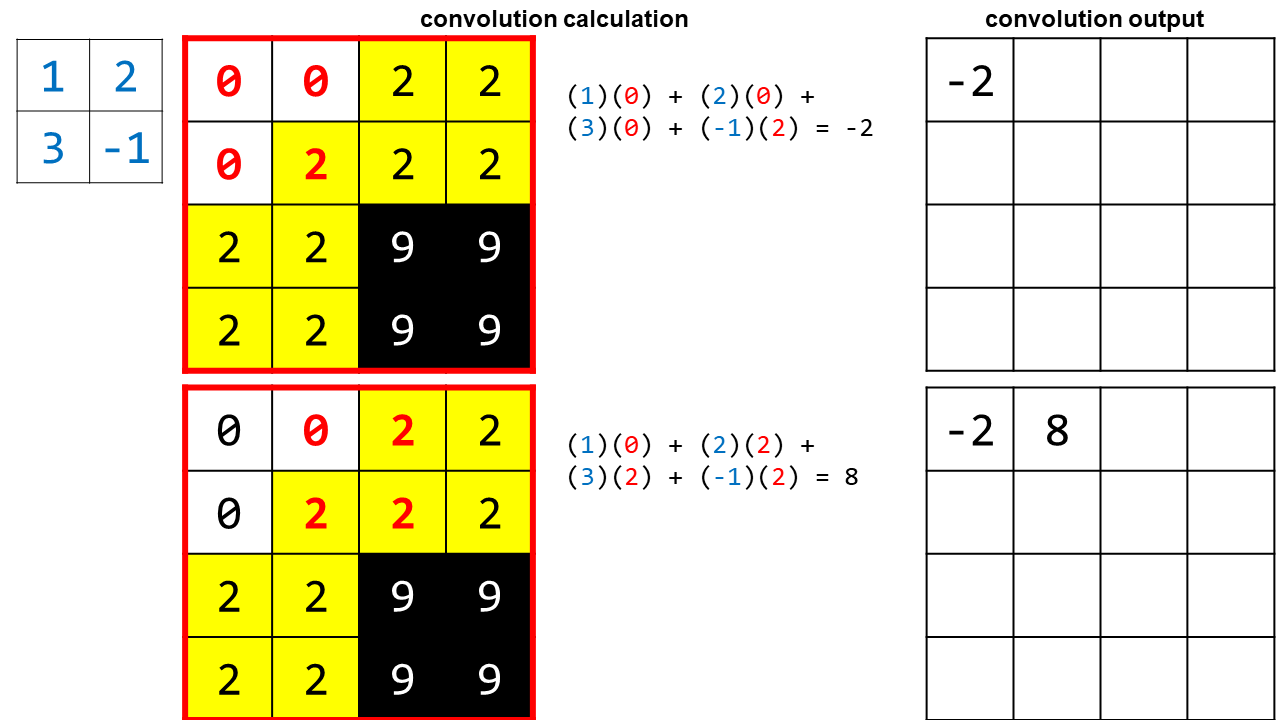
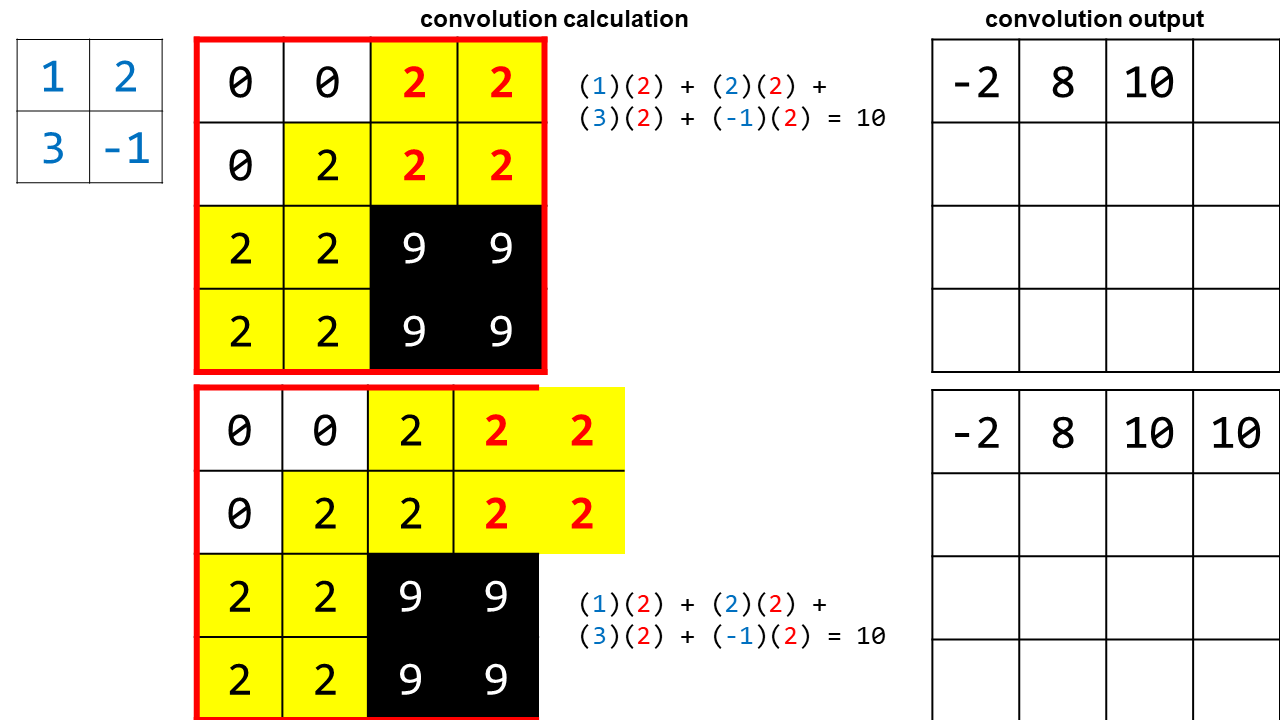
In the last part you can see that in order to get the last convolution value, the filter slid out of our original region. I show this because in practice we are applying convolution to the entire image, so there are still real pixels outside of the small area we’ve chosen to focus on for the purposes of the example. However, considering the image as a whole, we will eventually reach a “real edge” with our filter and we’ll have to stop. This means the output of our convolution will be slightly smaller than the original image.
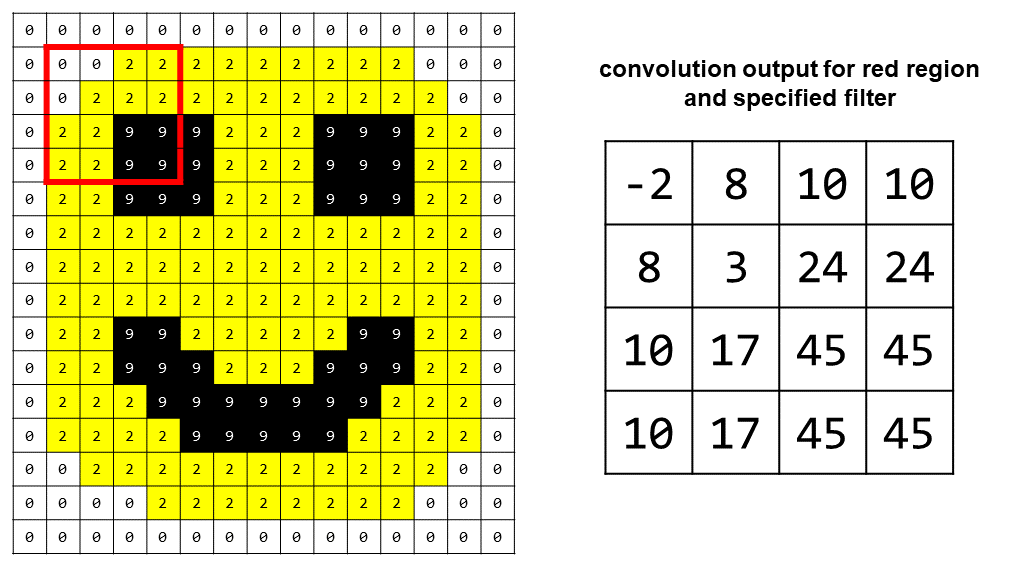
Here is the convolution output for the red region and the filter we chose:
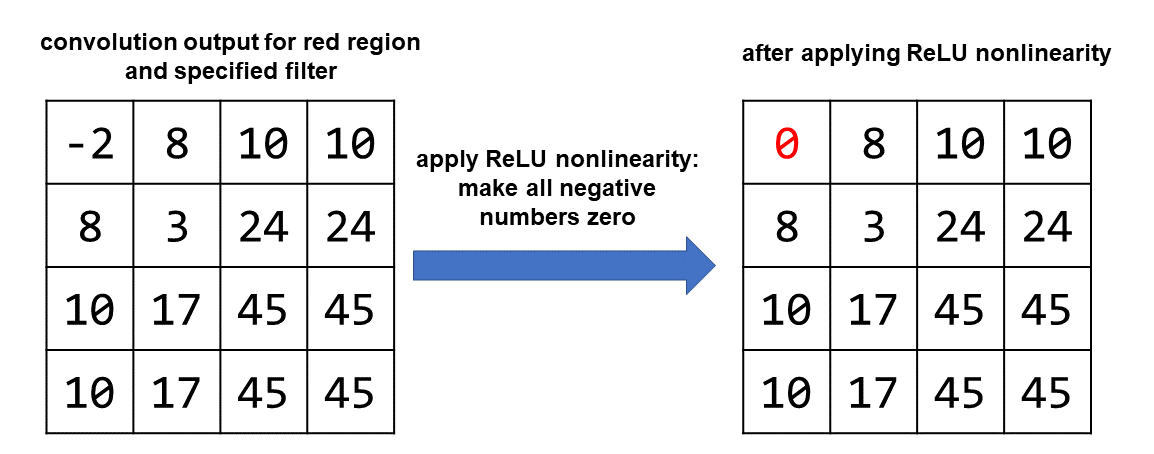
Nonlinearity
Once we’ve finished performing the convolution, we apply a “nonlinearity.” This is a nonlinear equation that will allow the CNN to learn more complicated patterns overall. One popular nonlinearity is ReLU, or “rectified linear unit.” It sounds fancy but it is simple: you replace each negative value with a zero.
Pooling
The last step is pooling. This step results in shrinking the size of the representation. Typically we choose a pooling window of the same dimension as the filter. We chose a 2 x 2 filter, so we choose a 2 x 2 pooling window.
Here we will perform “max pooling” where we choose the highest value in each pooling window.
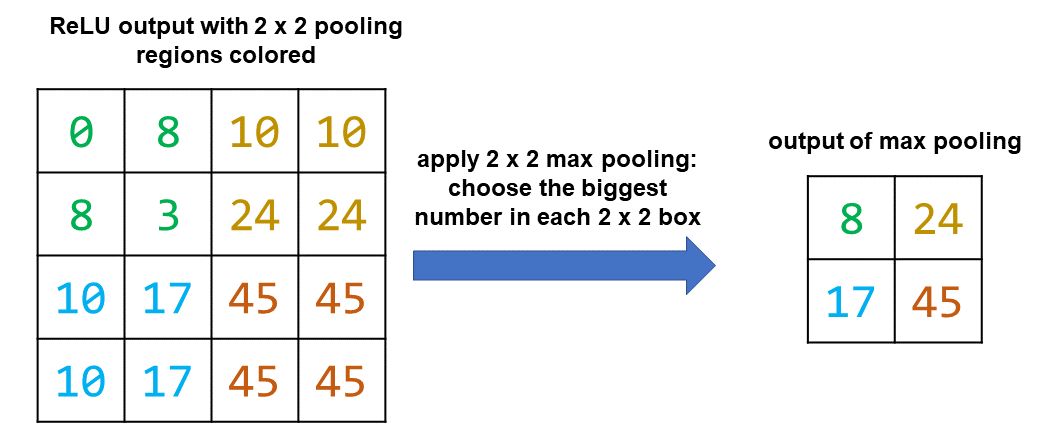
It’s also possible to perform other kinds of pooling, like average pooling, where we instead would take the average of all the values in the pooling window. Pooling is useful because it reduces the size of the representation, thereby reducing the amount of computation required overall.
There Are Many Filters In One Convolutional Layer
In the above example, we applied convolution, a nonlinearity, and pooling, to go from a 4 x 4 square of pixels to a 2 x 2 representation, focusing on just a single filter. However, in reality, one convolutional layer uses many different filters, all of the same size but with different values.
Let’s say that in our first convolutional layer we apply 32 different filters, each of size 2 x 2. Then the overall output size for the whole layer is 2 x 2 x 32. Each filter detects a different aspect of the image, because each filter contains different numbers.
There Are Many Layers in a CNN
We don’t stop once we have our 2 x 2 x 32 representation. Instead, we can do another round of convolution, nonlinearity, and pooling – this time applying the operations to the 2 x 2 x 32 representation, instead of the original image. This second round is a second “convolutional layer.” A modern CNN might have 8 layers or 99 layers, or any number of layers that the designer chooses.
The key idea behind CNNs with many layers is that the filters in the lower layers (closer to the input image) will learn simple characteristics like where the edges are, while the filters in higher layers (more abstract) will learn complicated characteristics like what human faces look like in photographs or what pneumonia looks like on a chest x-ray.
Visualizing Convolutional Filters
There are different ways to visualize what a CNN is seeing with its different filters. Figure 1 of this article shows how the first-layer filters of a CNN called AlexNet light up when looking at a picture of a cat. This article and this article contain additional filter visualizations. The video “Deep Visualization Toolbox” by Jason Yosinski, is definitely worth watching for a better understanding of how CNNs combine simple features (like edges) from the lower layers to detect complex features (like faces or books) with the filters of the higher layers.
Conclusions
CNNs are a powerful framework for understanding images, and involve repeated application of simple operations across many layers. They are in wide use in industry and academia, and have already begun to impact fields of medicine that rely on images including radiology, dermatology, and pathology.
Featured Image
The featured image is the Mona Lisa by Leonardo da Vinci, which I borrowed for the “emotion classification” example (for the irony, since people disagree about what emotion the Mona Lisa expresses, and also because I’ve been listening to a biography of Lenardo da Vinci in the car.) Here are some fun facts about the Mona Lisa:
- The Mona Lisa used to have eyebrows and eyelashes, but they were likely removed by accident when a curator cleaned the Mona Lisa’s eyes.
- The Isleworth Mona Lisa is thought to be an earlier version of the Mona Lisa by Leonardo da Vinci, depicting the same subject. It is a wider painting than the famous Mona Lisa and includes columns on either side of the subject.
- The Mona Lisa currently has a yellowish-brown hue. However, various studies suggest that the Mona Lisa used to be much more vividly-colored, with bright red and blue hues. She also likely has a fur coat in her lap.
Additional Resources
Over the past few years I’ve curated a list of particularly helpful resources related to CNNs. Here they are!
- “Convolutional Neural Networks (CNNs): An Illustrated Explanation” is an excellent blog post from the Association for Computing Machinery (ACM) providing details on CNN design and implementation.
- “A Beginner’s Guide to Understanding Convolutional Neural Networks” is another great post, particularly the section that uses a drawing of a mouse to explain how CNN filters work.
- Convolutional Neural Networks (CNNs / ConvNets): this article is from a Stanford course, CS 231n.
- vdumoulin/conv_arithmetic on Github contains awesome animations showing how different kinds of convolutional filters are applied to images. It includes some “fancy convolution” techniques like transposed convolution and dilated convolution. For more information on dilated convolution, check out “Understanding 2D Dilated Convolution Operation with Examples in Numpy and Tensorflow with Interactive Code”
- Chapter 9 of the Deep Learning book by Aaron C. Courville, Ian Goodfellow, and Yoshua Bengio, provides a more technical discussion of CNNs.
- Hvass-Labs/TensorFlow-Tutorials/02_Convolutional_Neural_Network.ipynb is a Python notebook with Tensorflow code for a CNN that solves the MNIST handwritten digits classification task.
- This paper, On Deep Learning for Medical Image Analysis (JAMA Guide to Statistics and Methods, 2018), is an overview of CNNs written for medical professionals. It also contains a great video explanation of CNNs. This article is behind a paywall, so if you are at a university you will have to log in to your university’s library resources to access it.
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments are closed.