

This post describes squeeze-and-excitation blocks, an architectural unit that can be plugged in to a convolutional neural network to improve performance with only a small increase in the total number of parameters. Squeeze-and-excitation blocks explicitly model channel relationships and channel interdependencies, and include a form of self-attention on channels.
The main reference for this post is the original paper, which has been cited over 2,500 times:
Overview
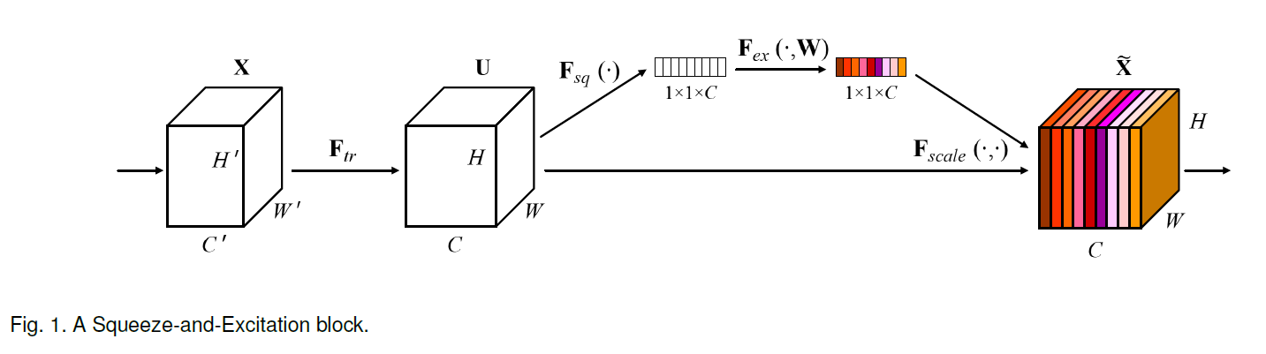
The Squeeze-and-Excitation (SE) block is intended to improve the quality of a convolutional neural network’s representations. A review of convolutional neural networks (CNNs) is available here.
For any layer of a convolutional neural network, we can build a corresponding SE block that recalibrates the feature maps:
- In the “squeeze” step, we use global average pooling to aggregate feature maps across their spatial dimensions H x W to produce a channel descriptor.
- In the “excitation” step, we apply fully-connected layers to the output of the “squeeze” step to produce a collection of per-channel weights (“activations”) that are applied to the feature maps to generate the final output of the SE block.
Figure 1 from the paper depicts an SE block:
Paper Notation & Review of 2D Convolution with Multiple Channels
Our input is an image X that has s channels:

We define a convolutional layer F_tr which consists of filters V:

We apply the convolutional layer F_tr consisting of filters V to our input image X.
To clarify the notation and the relationship between the input image X and the learned set of convolutional filters V, here is a quick review of 2D convolution for a multi-channel input image, in this case a 3-channel RGB input image.
The transformation F_tr includes multiple convolutional filters V=[v_1, v_2,…,v_C]. One filter for “2D convolution” of a 3-channel image is actually three-dimensional, as we can see from this animation where the sliding white outline represents a single filter, e.g. v_1:
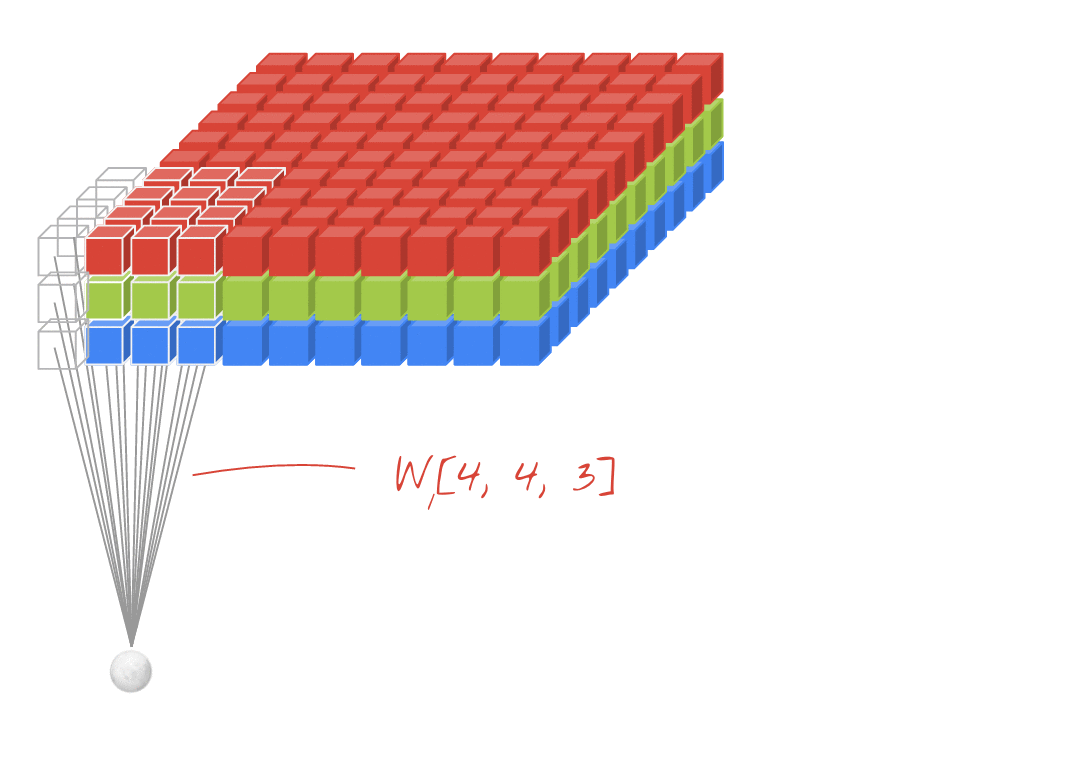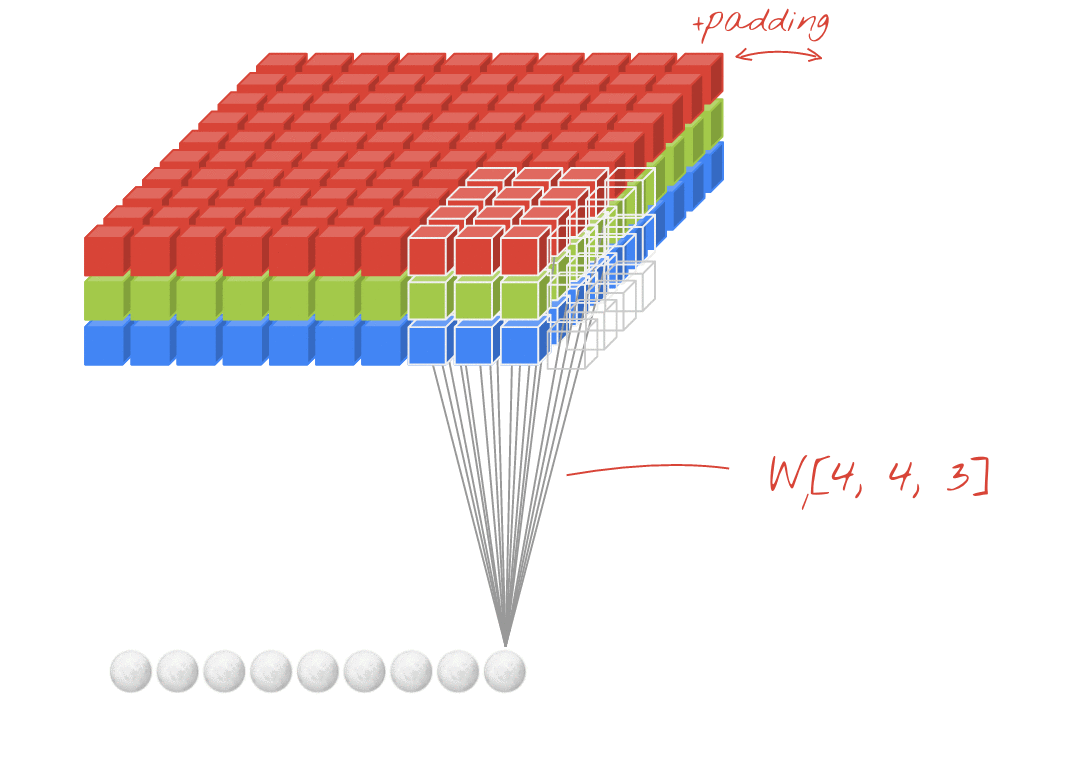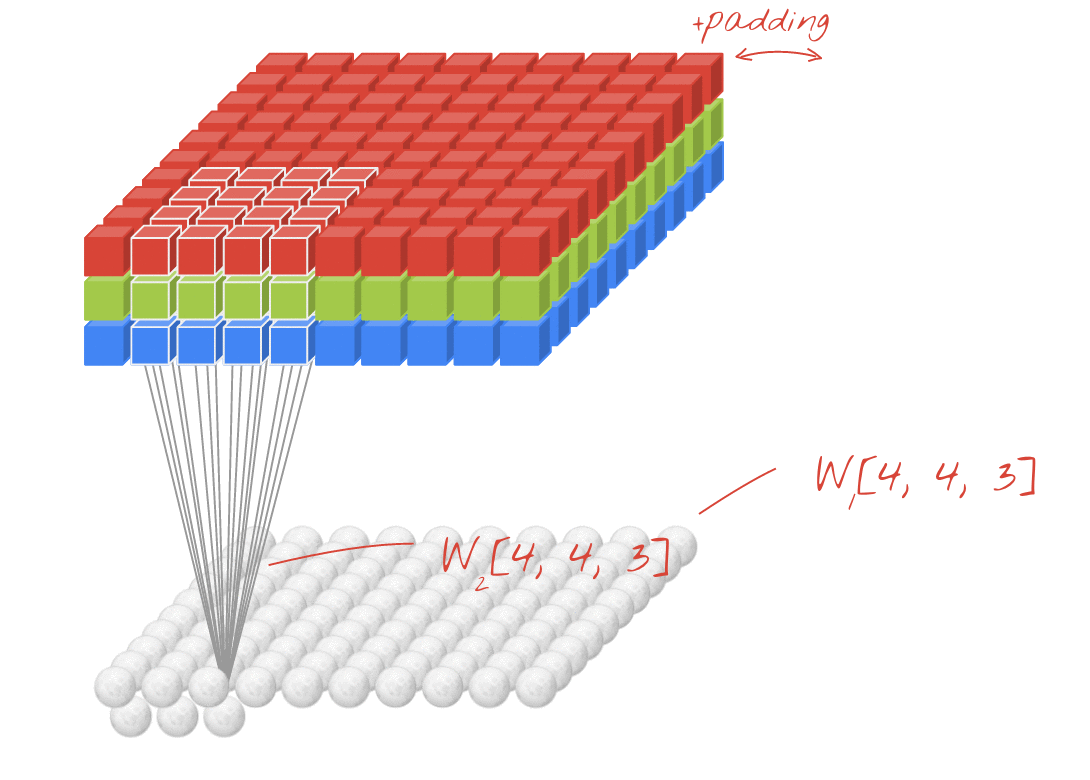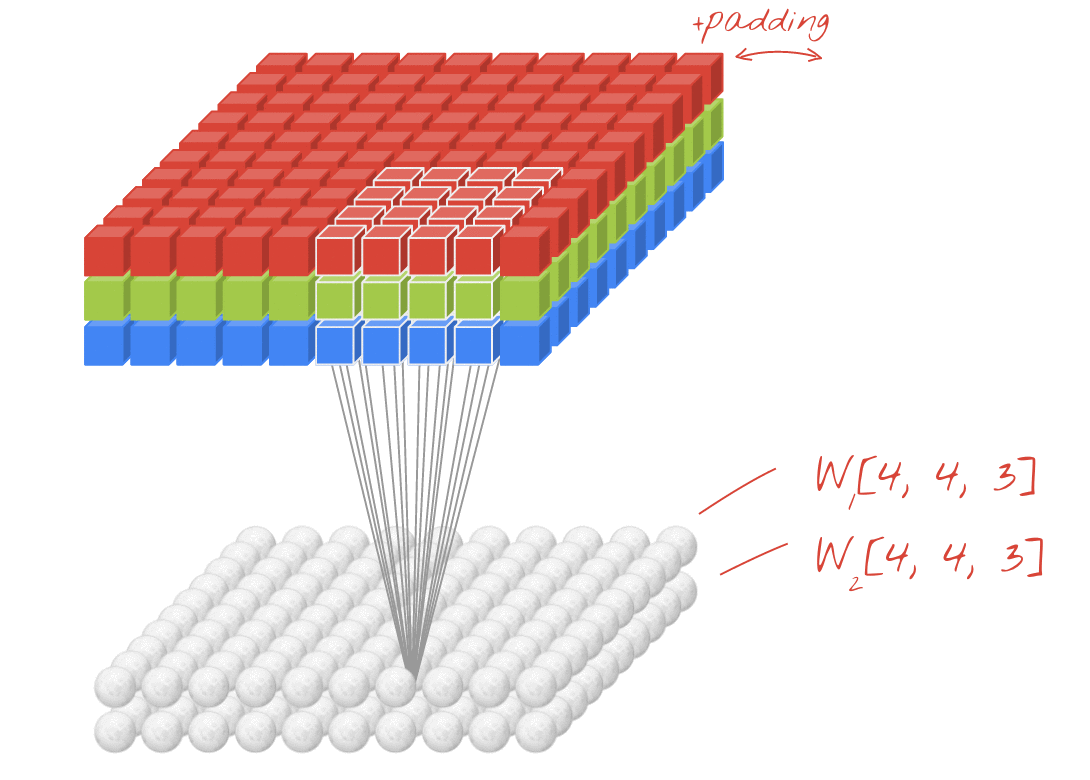
Animation created by Martin Görner. Original Link. Also available here.
Consider the RGB image X, shown twice in the picture below – once at the top with a pale orange filter v_1 overlaid, and once at the bottom with a purple filter v_2 overlaid:
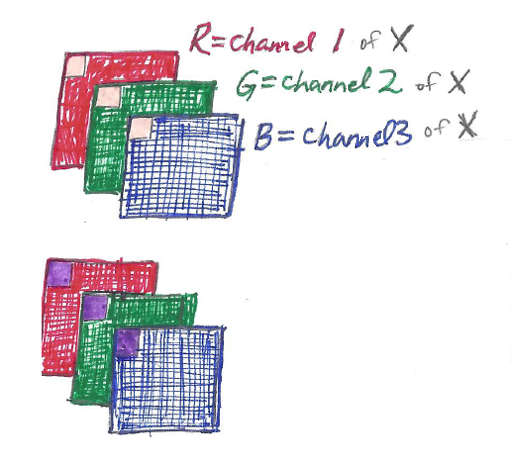
We can see from the diagram above that a single filter is three-dimensional, measuring k x k x 3 for the 3 channels of X. In this example V includes two filters, the pale orange filter v_1 and the purple filter v_2.
In the paper’s notation, superscript s is used to keep track of input X’s channels (in this case s=1,2,3), while subscript c is used to keep track of the filters in V (in this case c=1,2):


Here are the filters labeled in detail:
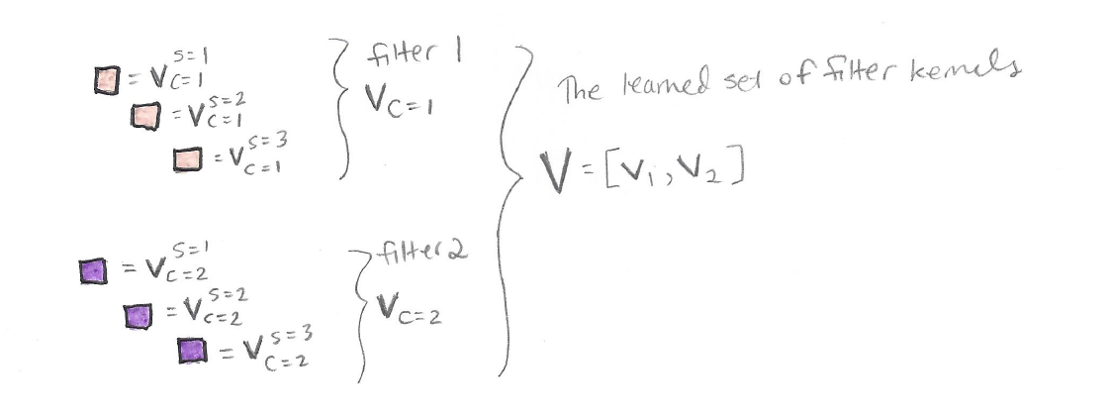
By applying the filters V to input image X, we obtain output filter maps U:

A single output filter map, e.g. u_1 (subscript c=1), is produced by a summation through all channels (i.e. through superscripts s=1, s=2, and s=3). Only implicit channel relationships can be captured in this manner. To quote the authors,
Since the output is produced by a summation through all channels, channel dependencies are implicitly embedded in v_c, but are entangled with the local spatial correlation captured by the filters. The channel relationships modeled by convolution are inherently implicit and local (except the ones at top-most layers). We expect the learning of convolutional features to be enhanced by explicitly modeling channel interdependencies [i.e., with SE blocks].
(Note: following the paper, bias terms have been omitted to simplify notation.)
Now that we’ve reviewed the paper’s notation and 2D multi-channel convolution, here’s an explanation of how squeeze-and-excitation blocks work. They are surprisingly simple, requiring only global average pooling and fully connected layers.
Squeeze: Global Information Embedding
The “squeeze” step in the SE block squeezes global spatial information into a channel descriptor. The squeeze step consists of global average pooling across the spatial dimensions H x W, to produce channel-wise statistics. Here’s an excerpt from the paper with the description and equation for the squeeze step:

The following sketch illustrates the squeeze operation which reduces each distinct H x W feature map u_c into a scalar channel descriptor z_c:
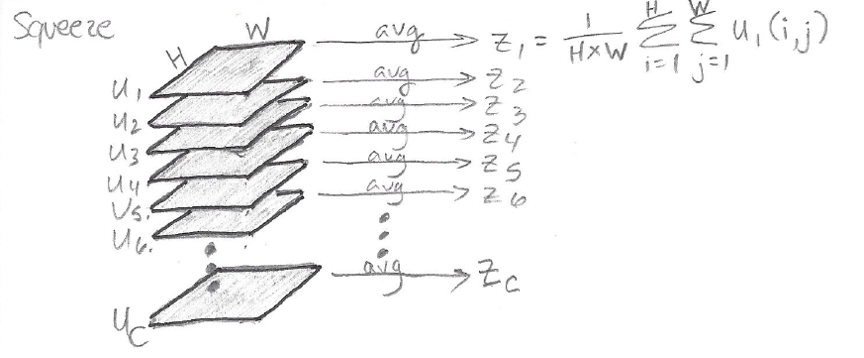
The scalars [z_1, z_2 ,…, z_C] together form a vector z of length C which will be used in the excitation step. Note that that z captures global information in the sense that each element of z is produced by an aggregation across the full feature map height H and full feature map width W.
Excitation: Adaptive Recalibration
The excitation operation is intended to fully capture channel-wise dependencies. The excitation operation processes the output of the squeeze step (the vector z) to produce a vector of activations s, which is then used to re-scale the feature maps. (This activations vector s is not to be confused with the s that was used earlier to keep track of the channels of input X).
The vector s is calculated from the squeeze output z using two fully-connected layers with a bottleneck that takes the representation down to size C/r:
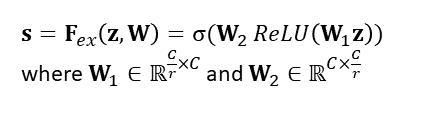
The hyperparameter r is referred to as the “reduction ratio.” If r is bigger, then the intermediate representation is smaller. The goal of reducing the size of the representation to C/r and then expanding it back up to C is to (a) limit model complexity and (b) aid generalization. As the authors put it, the reduction ratio r “allows us to vary the capacity and computational cost of the SE blocks in the network.”
Here is a sketch of the first part of the excitation step, in which the activations in s are calculated from the squeeze output z:
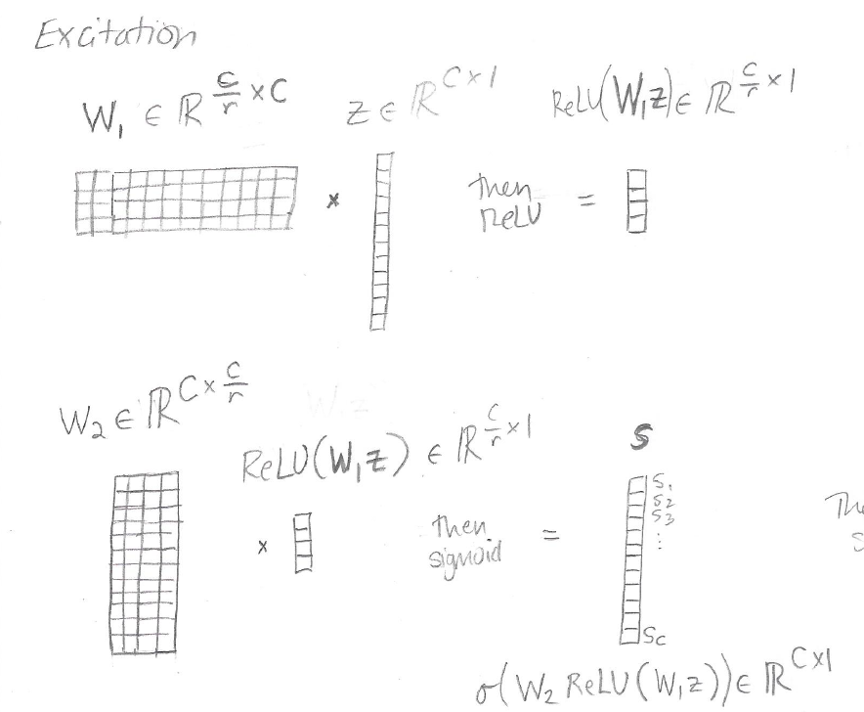
Once s is calculated, the elements of s are used to rescale the feature maps of U to obtain the final output of the SE block, termed X-tilde:

Here’s a sketch of the final step:
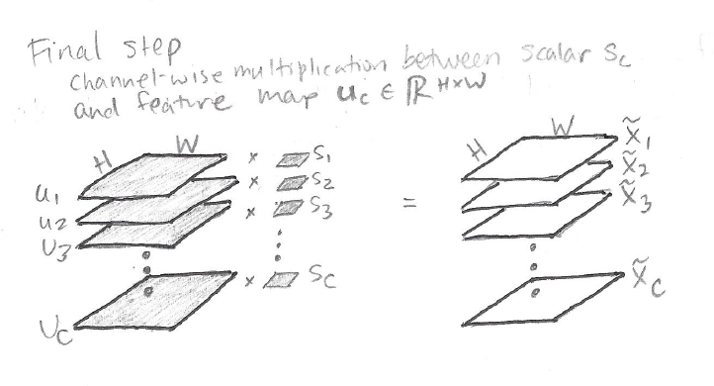
As you can see from the sketch, the activation s_1 has to be tiled across the H x W map u_1 so that s_1 element-wise multiplies all the values in u_1 to produce x-tilde_1.
The stack of recalibrated feature maps [x-tilde_1,x-tilde_2,…,x-tilde_C] then continue through the rest of the CNN, as they are exactly the same dimension as the original feature maps [u_1,u_2,…,u_C].
Thus, SE blocks add a form of self-attention to the CNN:
SE blocks intrinsically introduce dynamics conditioned on the input, which can be regarded as a self-attention function on channels whose relationships are not confined to the local receptive field the convolutional filters are responsive to.
Implementation
A squeeze-and-excitation block can be plugged in to any CNN architecture. Figure 3 from the paper illustrates how to use an SE block in a ResNet:
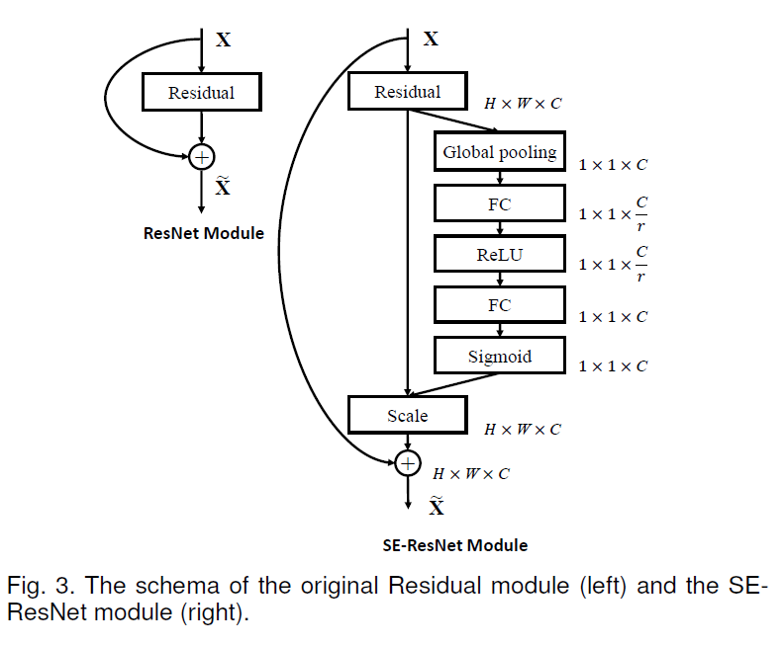
SE blocks do not increase the computational complexity of the model very much. In the following comparisons, “SE-ResNet-50” refers to a ResNet-50 model with SE blocks added, and “vanilla ResNet-50” refers to the baseline ResNet-50 without any SE blocks:
- SE-ResNet-50 requires ~3.87 GFLOPs vs. ~3.86 GFLOPs for vanilla ResNet-50, a 0.26% relative increase (for a single forward pass of a 224 x 224 pixel input image);
- SE-ResNet-50 requires 209 ms for a single pass forwards and backwards, vs. 190 ms for vanilla ResNet-50, a 10% relative increase (timings on a server with 8 NVIDIA Titan X GPUs for a training minibatch of 256 images);
- SE-ResNet-50 requires ~27.5 million parameters, vs. ~25 million for vanilla ResNet-50, a 10% relative increase. “In practice, the majority of these parameters come from the final stage of the network, where the excitation operation is performed across the greatest number of channels. […] This comparatively costly final stage of SE blocks could be removed at only a small cost in performance (<0.1% top-5 error on ImageNet) reducing the relative parameter increase to ~4%”
Here’s an example implementation of an SE block (source):
def se_block(in_block, ch, ratio=16):
x = GlobalAveragePooling2D()(in_block)
x = Dense(ch//ratio, activation=’relu’)(x)
x = Dense(ch, activation=’sigmoid’)(x)
return multiply()([in_block, x])
Results
The authors add SE blocks to ResNet architectures, ResNeXt architectures, VGG-16, and Inception architectures, and show that the addition of SE blocks improves performance on ImageNet classification. The performance improvement is shown in parentheses next to each entry in the SENet columns in Table 2:
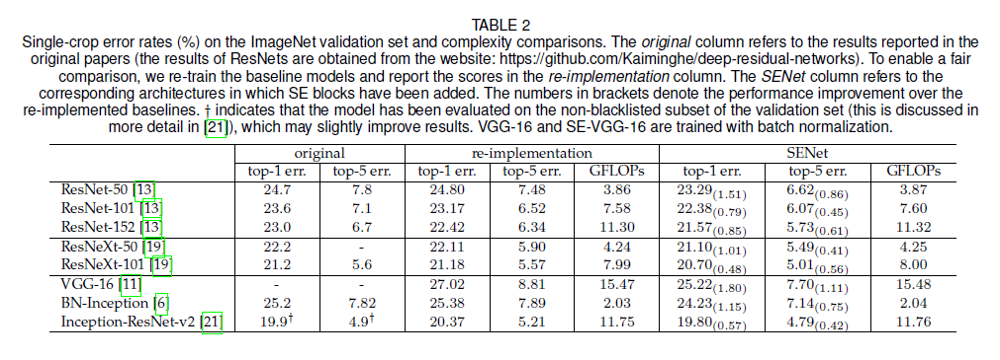
Additional takeaways from the results section:
- SE blocks also improve model performance on CIFAR-10 and CIFAR-100 datasets, the Places365-Challenge dataset for scene classification, and the COCO dataset for object detection.
- Performance is robust to a range of different values of the reduction ratio r. “Increased complexity does not improve performance monotonically while a smaller ratio dramatically increases the parameter size of the model. Setting r=16 achieves a good balance between accuracy and complexity.”
- For the squeeze operator, global average pooling achieves slightly better performance than global max pooling.
- The excitation operator has a ReLU on the inside, and the final non-linearity is a sigmoid. Replacing the final non-linearity of the excitation operator with a ReLU or Tanh (instead of a sigmoid) worsens the performance.
Summary
- Squeeze-and-excitation blocks explicitly model channel relationships and channel interdependencies and include a form of self-attention on channels;
- Squeeze-and-excitation blocks recalibrate the feature maps using a “squeeze” operation of global average pooling, followed by an “excitation” operation that uses two fully connected layers;
- Squeeze-and-excitation blocks can be plugged in to any CNN architecture and require minimal computational overhead;
- Squeeze-and-excitation blocks can improve performance on classification and object detection tasks.
About the Featured Image
The featured image depicts fireworks over Sydney Harbor and is by Rob Chandler (Wikipedia CC by 2.0) because fireworks are exciting and so are squeeze-and-excitation blocks.
As an independent researcher (MD + AI PhD + 7 yrs prior founder/CEO experience), I build and evaluate cutting-edge healthcare AI for startups. Contact me to learn more.
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

{kind=link}