
This article will cover the relationships between the negative log likelihood, entropy, softmax vs. sigmoid cross-entropy loss, maximum likelihood estimation, Kullback-Leibler (KL) divergence, logistic regression, and neural networks. If you are not familiar with the connections between these topics, then this article is for you!
Recommended Background
- Basic understanding of neural networks. If you would like more background in this area please read Introduction to Neural Networks.
- Thorough understanding of the difference between multiclass and multilabel classification. If you are not familiar with this topic, please read the article Multi-label vs. Multi-class Classification: Sigmoid vs. Softmax. The short refresher is as follows: in multiclass classification we want to assign a single class to an input, so we apply a softmax function to the raw output of our neural network. In multilabel classification we want to assign multiple classes to an input, so we apply an element-wise sigmoid function to the raw output of our neural network.
Problem Setup: Multiclass Classification with a Neural Network
First we will use a multiclass classification problem to understand the relationship between log likelihood and cross entropy. Here’s our problem setup:


Cat image source: Wikipedia.
Likelihood
Let’s say we’ve chosen a particular neural network architecture to solve this multiclass classification problem – for example, VGG, ResNet, GoogLeNet, etc. Our chosen architecture represents a family of possible models, where each member of the family has different weights (different parameters) and therefore represents a different relationship between the input image x and some output class predictions y. We want to choose the member of the family that has a good set of parameters for solving our particular problem of [image] –> [airplane, train, or cat].
One way of choosing good parameters to solve our task is to choose the parameters that maximize the likelihood of the observed data:

Negative Log Likelihood
The negative log likelihood is then, literally, the negative of the log of the likelihood:

Reference for Setup, Likelihood, and Negative Log Likelihood: “Cross entropy and log likelihood” by Andrew Webb
Side Note on Maximum Likelihood Estimation (MLE)
Why do we “minimize the negative log likelihood” instead of “maximizing the likelihood” when these are mathematically the same? It’s because we typically minimize loss functions, so we talk about the “negative log likelihood” because we can minimize it. (Source: CrossValidated.)
Thus, when you minimize the negative log likelihood, you are performing maximum likelihood estimation. Per the Wikipedia article on MLE,
maximum likelihood estimation (MLE) is a method of estimating the parameters of a probability distribution by maximizing a likelihood function, so that under the assumed statistical model the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. […] From the point of view of Bayesian inference, MLE is a special case of maximum a posteriori estimation (MAP) that assumes a uniform prior distribution of the parameters.
And here’s another summary from Jonathan Gordon on Quora:
Maximizing the (log) likelihood is equivalent to minimizing the binary cross entropy. There is literally no difference between the two objective functions, so there can be no difference between the resulting model or its characteristics.
This of course, can be extended quite simply to the multiclass case using softmax cross-entropy and the so-called multinoulli likelihood, so there is no difference when doing this for multiclass cases as is typical in, say, neural networks.
The difference between MLE and cross-entropy is that MLE represents a structured and principled approach to modeling and training, and binary/softmax cross-entropy simply represent special cases of that applied to problems that people typically care about.
Entropy
After that aside on maximum likelihood estimation, let’s delve more into the relationship between negative log likelihood and cross entropy. First, we’ll define entropy:

Cross Entropy

Section references: Wikipedia Cross entropy, “Cross entropy and log likelihood” by Andrew Webb
Kullback-Leibler (KL) Divergence
The Kullback-Leibler (KL) divergence is often conceptualized as a measurement of how one probability distribution differs from a second probability distribution, i.e. as a measurement of the distance between two probability distributions. Technically speaking, KL divergence is not a true metric because it doesn’t obey the triangle inequality and D_KL(g||f) does not equal D_KL(f||g) — but still, intuitively it may seem like a more natural way of representing a loss, since we want the distribution our model learns to be very similar to the true distribution (i.e. we want the KL divergence to be small – we want to minimize the KL divergence.)
Here’s the equation for KL divergence, which can be interpreted as the expected number of additional bits needed to communicate the value taken by random variable X (distributed as g(x)) if we use the optimal encoding for f(x) rather than the optimal encoding for g(x):

Additional ways to think about KL divergence D_KL (g||f):
- it’s the relative entropy of g with respect to f
- it’s a measure of the information gained when one revises one’s beliefs from the prior probability distribution f to the posterior probability distribution g
- it’s the amount of information lost when f is used to approximate g
In machine learning, g typically represents the true distribution of data, while f represents the model’s approximation of the distribution. Thus for our neural network we can write the KL divergence like this:
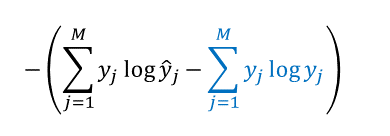
Notice that the second term (colored in blue) depends only on the data, which are fixed. Because this second term does NOT depend on the likelihood y-hat (the predicted probabilities), it also doesn’t depend on the parameters of the model. Therefore, the parameters that minimize the KL divergence are the same as the parameters that minimize the cross entropy and the negative log likelihood! This means we can minimize a cross-entropy loss function and get the same parameters that we would’ve gotten by minimizing the KL divergence.
Section references: Wikipedia Kullback-Leibler divergence, “Cross entropy and log likelihood” by Andrew Webb
What about “sigmoid cross entropy loss”?
So far, we have focused on “softmax cross entropy loss” in the context of a multiclass classification problem. However, when training a multilabel classification model, in which more than one output class is possible, then a “sigmoid cross entropy loss” is used instead of a “softmax cross entropy loss.” Please see this article for more background on multilabel vs. multiclass classification.
As we just saw, cross-entropy is defined between two probability distributions f(x) and g(x). But this doesn’t make sense in the context of a sigmoid applied at the output layer, since the sum of the output decimals won’t be 1, and therefore we don’t really have an output “distribution.”
Per Michael Nielsen’s book, chapter 3 equation 63, one valid way to think about the sigmoid cross entropy loss is as “a summed set of per-neuron cross-entropies, with the activation of each neuron being interpreted as part of a two-element probability distribution.”
So, instead of thinking of a probability distribution across all output neurons (which is completely fine in the softmax cross entropy case), for the sigmoid cross entropy case we will think about a bunch of probability distributions, where each neuron is conceptually representing one part of a two-element probability distribution.
For example, let’s say we feed the following picture to a multilabel image classification neural network which is trained with a sigmoid cross-entropy loss:

Image Source: Wikipedia.
Our network has output neurons corresponding to the classes cat, dog, couch, airplane, train, and car.
After applying a sigmoid function to the raw value of the cat neuron, we get 0.8 as our value. We can consider this 0.8 to be the probability of class “cat” and we can imagine an implicit probability value of 1 – 0.8 = 0.2 as the probability of class “NO cat.” This implicit probability value does NOT correspond to an actual neuron in the network. It’s only imagined/hypothetical.
Similarly, after applying a sigmoid function to the raw value of the dog neuron, we get 0.9 as our value. We can consider this 0.9 to be the probability of class “dog” and we can imagine an implicit probability value of 1 – 0.9 = 0.1 as the probability of class “NO dog.”
For the airplane neuron, we get a probability of 0.01 out. This means we have a 1 – 0.01 = 0.99 probability of “NO airplane” – and so on, for all the output neurons. Thus, each neuron has its own “cross entropy loss” and we just sum together the cross entropies of each neuron to get our total sigmoid cross entropy loss.
We can write out the sigmoid cross entropy loss for this network as follows:

“Sigmoid cross entropy” is sometimes referred to as “binary cross-entropy.” This article discusses “binary cross-entropy” for multilabel classification problems and includes the equation.
Connections Between Logistic Regression, Neural Networks, Cross Entropy, and Negative Log Likelihood
- If a neural network has no hidden layers and the raw output vector has a softmax applied, then that is equivalent to multinomial logistic regression
- if a neural network has no hidden layers and the raw output is a single value with a sigmoid applied (a logistic function) then this is logistic regression
- thus, logistic regression is just a special case of a neural network! (refA, refB)
- if a neural network does have hidden layers and the raw output vector has a softmax applied, and it’s trained using a cross-entropy loss, then this is a “softmax cross entropy loss” which can be interpreted as a negative log likelihood because the softmax creates a probability distribution.
- if a neural network does have hidden layers and the raw output vector has element-wise sigmoids applied, and it’s trained using a cross-entropy loss, then this is a “sigmoid cross entropy loss” which CANNOT be interpreted as a negative log likelihood, because there is no probability distribution across all the examples. The outputs don’t sum to one. Here we need to use the interpretation provided in the previous section, in which we conceptualize the loss as a bunch of per-neuron cross entropies that are summed together.
Section reference: Stats StackExchange
For additional info you can look at the Wikipedia article on Cross entropy, specifically the final section which is entitled “Cross-entropy loss function and logistic regression.” This section describes how the typical loss function used in logistic regression is computed as the average of all cross-entropies in the sample (“sigmoid cross entropy loss” above.) The cross-entropy loss is sometimes called the “logistic loss” or the “log loss”, and the sigmoid function is also called the “logistic function.”
Cross Entropy Implementations
In Pytorch, there are several implementations for cross-entropy:
Implementation A:torch.nn.functional.binary_cross_entropy (seetorch.nn.BCELoss): the input values to this function have already had a sigmoid applied, e.g.
>>> m = nn.Sigmoid() >>> loss = nn.BCELoss() >>> input = torch.randn(3, requires_grad=True) >>> target = torch.empty(3).random_(2) >>> output = loss(m(input), target) >>> output.backward()
Implementation B:torch.nn.functional.binary_cross_entropy_with_logits(see torch.nn.BCEWithLogitsLoss): “this loss combines a Sigmoid layer and the BCELoss in one single class. This version is more numerically stable than using a plain Sigmoid followed by a BCELoss as, by combining the operations into one layer, we take advantage of the log-sum-exp trick for numerical stability.”
Implementation C:torch.nn.functional.nll_loss(see torch.nn.NLLLoss) : “the negative log likelihood loss. It is useful to train a classification problem with C classes. […] The input given through a forward call is expected to contain log-probabilities of each class.”
Implementation D: torch.nn.functional.cross_entropy(see torch.nn.CrossEntropyLoss): “this criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class. It is useful when training a classification problem with C classes. […] The input is expected to contain raw, unnormalized scores for each class.”
Conclusion
There are fundamental relationships between negative log likelihood, cross entropy, KL divergence, neural networks, and logistic regression as we have discussed here. I hope you have enjoyed learning about the connections between these different models and losses!
About the Featured Image
Since the topic of this post was connections, the featured image is a “connectome.” A connectome is “a comprehensive map of neural connections in the brain, and may be thought of as its ‘wiring diagram.'” Reference: Wikipedia. Featured Image Source: The Human Connectome.
As an independent researcher (MD + AI PhD + 7 yrs prior founder/CEO experience), I build and evaluate cutting-edge healthcare AI for startups. Contact me to learn more.
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

{kind=link}
{kind=link}
{kind=link}
Comments are closed.