

In this post, we’ll compare three related but distinct computer vision tasks that can be tackled with convolutional neural networks: image classification model explanation, weakly supervised segmentation, and fully supervised segmentation. We will consider the similarities and differences in goal, training data, and methods. Note that I’ll be focused on a neural network approach to these tasks although it’s true that all three tasks can be tackled through non-neural-net methods.
If you would like to cite this post, it’s based on an excerpt from my paper, “Use HiResCAM instead of Grad-CAM for faithful explanations of convolutional neural networks”.
This post will use a running example based on this boat image sketch:

Goals
First, let’s consider the goals:
- Model explanation: highlight regions a model used to predict an object
- Weakly supervised or fully supervised segmentation: identify all pixels that are part of an object
The philosophical difference in goals has important implications for judging the success of the task, discussed in more detail next.
The goal of model explanation
The goal of model explanation is to demonstrate what locations in an image a model used to make a particular prediction – even if that means highlighting areas outside of the relevant object. For example, if a model has used tracks to identify a train, the explanation should highlight the tracks. If the model has used water to identify a boat, the explanation should highlight the water.

Any performance metric to evaluate explanation correctness (“explanation quality”) thus must be calculated against a ground truth of “locations the model used for each prediction” which in turn can only be uncovered through mathematical properties of a model and an explanation method. For example, in the HiResCAM paper, we proved that HiResCAM exactly explains locations used by CNNs ending in one fully connected layer.
“Locations the model used” may not have any relation to object segmentation maps, nor can these locations be created manually by a human, for if humans were able to understand models well enough to circumscribe regions used for each prediction then there would be no need for explanation methods in the first place.
The goal of segmentation
The goal of segmentation is to identify all pixels that are part of an object.
In weakly supervised segmentation, this goal must be accomplished using only whole image labels. In fully supervised segmentation, ground truth segmentation maps are available for training.

Because weakly supervised segmentation maps derived from image classifiers are “fuzzy” and often tend to focus on small discriminative parts of objects, weakly supervised segmentation methods include thresholding and post-processing steps intended to transform/expand the raw “fuzzy” segmentation map into a sharper and more accurate map (e.g., by using conditional random fields).

IoU must not be used to evaluate explanation correctness
One common performance metric for segmentation tasks is intersection-over-union (IoU), which is highest when the predicted segmentation for a class fully overlaps the ground truth segmentation for that class without spreading to other regions.
The IoU is calculated by comparing the pixels in the model’s predicted segmentation with the pixels in the ground truth segmentation. The true positives “tp” (pixels in the prediction and the ground truth), false positives “fp” (pixels in the prediction NOT in the ground truth), and false negatives “fn” (pixels NOT in the prediction but present in the ground truth) are used to calculate IoU as shown in the following diagram, which is a cartoon of the lungs and heart assuming a medical image classification task:
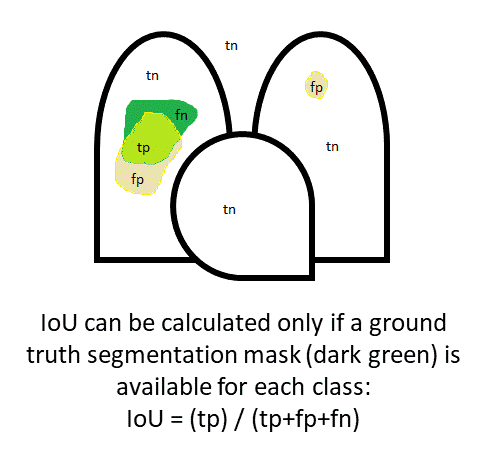
While IoU is a reasonable metric for judging segmentation performance, IoU should never be used to evaluate explanation correctness. Unfortunately, some papers attempt to experimentally evaluate explanation correctness using IoU calculated against ground truth object segmentations, or using the closely related setup of asking humans to subjectively judge how well explanations correspond to an object (which in effect corresponds to humans estimating an IoU-like quantity). The unspoken assumption in these experiments is that the classification model is always using the relevant object to predict the class and so a “good” explanation method will achieve a high IoU. However, as mentioned previously, models are NOT guaranteed to always use the relevant object to predict the class, and indeed, the possibility for undesirable model behavior is a primary motivator behind development of explanation methods.
Any time a model behaves unexpectedly or exploits spurious correlations, the IoU of a truthful model explanation will be low, but it would be false to then conclude that the low IoU means the explanation was of poor quality. The only way to know if an explanation method is faithful to a particular type of model is to prove it, based on the definition of the model and the definition of the explanation method.
IoU of a faithful explanation method provides insight into a model
Although IoU cannot be used to evaluate the quality of an explanation method, IoU calculated based on an explanation method with guaranteed properties (e.g. CAM or HiResCAM) can be used to evaluate a particular model. In these cases, high IoU indicates that the model tends to make predictions using areas within the objects of interest, as desired, while low IoU indicates that the model tends to make predictions using areas outside the object of interest and thus is exploiting background or correlated objects.
Methods
Now that we’ve overviewed the differing goals and evaluations of explanation vs. segmentation, let’s consider methods that are used for each task.
Model explanation can be accomplished through techniques like saliency maps, CAM, and HiResCAM; saliency maps pass sanity checks and both CAM and HiResCAM have guaranteed faithfulness properties. Grad-CAM is commonly used as an explanation technique, but in fact is not appropriate to use for model explanation because it sometimes highlights regions that the model did not actually use for prediction. Other model explanation methods have been shown to act more like edge detectors than explanations, so it’s very important when selecting a model explanation method to choose one with guaranteed properties to avoid producing misleading explanations that obscure what the model is really doing.
Weakly-supervised segmentation methods, somewhat confusingly, are often built off of CAM-family explanation methods, and thus many weakly-supervised segmentation methods have “CAM” in their name even though their goal is segmentation and not model explanation: e.g., Mixup-CAM, Sub-Category CAM, and Puzzle-CAM. It is critical to keep in mind that even though these weakly supervised segmentation approaches are leveraging model explanation methods, they have a fundamentally different goal.
Fully supervised segmentation models like U-Nets or Mask R-CNNs make use of ground truth segmentation masks. Fully supervised segmentation models typically outperform weakly supervised segmentation models, because fully supervised models have much more information available. As noted above, weakly supervised segmentation maps are derived from classification models trained only on presence/absence labels – for example, “boat=1” or “boat=0” for the whole image. Fully supervised segmentation models are trained on pixel-level labels; a typical RGB natural image may have on the order of 256 x 256 = 65,536 pixels. Thus a fully supervised segmentation model is trained on orders of magnitude more information than a weakly supervised segmentation model. The downside to fully supervised segmentation is the expense of obtaining the pixel-level labels, which limits the number of training examples and the number of different classes that can be considered.
Summary
The table below summarizes the similarities and differences between the tasks:

Happy explaining and segmenting!
About the Featured Image
The featured image (sky puzzle) is from Wikipedia (Creative Commons license).
As an independent researcher (MD + AI PhD + 7 yrs prior founder/CEO experience), I build and evaluate cutting-edge healthcare AI for startups. Contact me to learn more.
Want to be the first to hear about my articles bridging healthcare, artificial intelligence, and business—and get a free list of my favorite health AI resources? Sign up here.

{kind=link}